硬件
半导体
并行计算
vectorization
原文链接
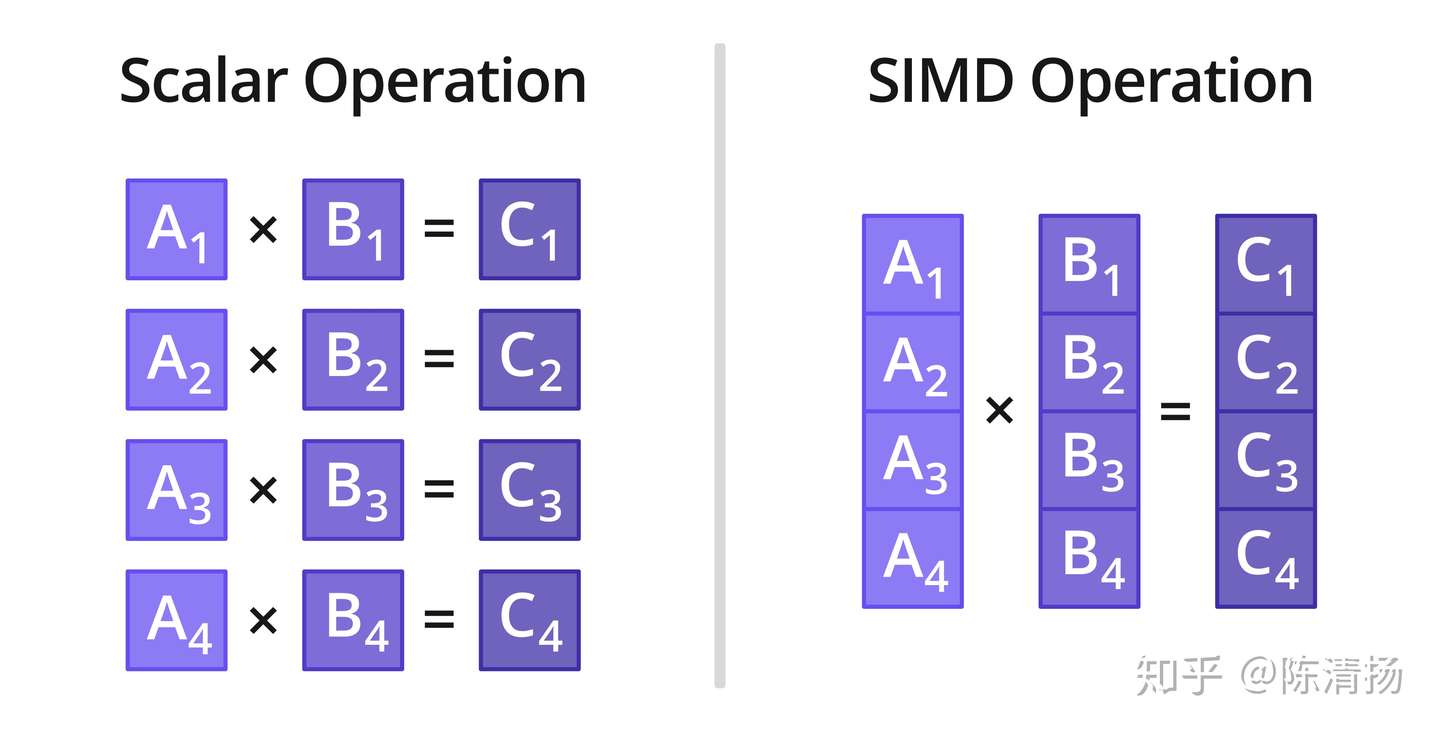
向量化即“批量操作”,批量操作在物理生活中也很常见,在计算机中最常见的执行模型就是SIMD(Single Instruction Multiple Data),即对批量的数据同时进行同样的操作以提高效率。如下图中左边的机器一次只能计算一对标量的相乘,于是四对数相乘就要算四次,而右边的机器能直接同时处理四个数,一次操作就能完成四对数相乘。
Cache-efficient
高速缓存
RAM(Random Access Memory)
随机存储器,俗称内存,我们常说的电脑内存8g,指的就是这个(也不完全正确)。RAM要求每时每刻都不断地供电,否则数据会丢失。它由半导体材料制作,是计算机的工作场所。
ROM(Read Only Memory)
只读存储器,应用于硬盘存储。一般由磁性材料制作,用来存放暂时不用的信息,只有加载到内存(RAM)中才能被CPU处理。即CPU与硬盘不发生直接的数据交换。
Cache (高速缓冲存储器)
Cache介于CPU与RAM之间,是一个读写速度比RAM更快的存储器。当CPU向RAM中写入或读出数据时会同步存储进Cache中,当CPU再次需要这些数据时,CPU就从Cache读取数据,而不是访问较慢的内存,如需要的数据在Cache中没有,CPU会再去读取Cache中的数据。
访问速度
Cache>>RAM>>ROM
field solvers
求解某个方程的可执行程序
直接翻译为场求解器,需要看一些cfd对于field的相关解释,和网格有关系。
下面是wiki对于Electromagnetic field solver的解释:
电磁场求解器(或有时只是场求解器)是直接求解麦克斯韦方程组(麦克斯韦方程组的子集)的专用程序。
计算机
I/O
I/O就是简单的数据Copy,仅此而已。
如果数据是从外部设备copy到内存中,这就是Input。
如果数据是从内存copy到外部设备,这就是Output。
内存与外部设备之间的数据copy就是I/O(Input/Output)
race condition
简洁版:
两个线程访问共性数据(变量),并在同一时间对其修改
长版:
A race condition occurs when two or more threads can access shared data and they try to change it at the same time. Because the thread scheduling algorithm can swap between threads at any time, you don’t know the order in which the threads will attempt to access the shared data. Therefore, the result of the change in data is dependent on the thread scheduling algorithm, i.e. both threads are “racing” to access/change the data.
Problems often occur when one thread does a “check-then-act” (e.g. “check” if the value is X, then “act” to do something that depends on the value being X) and another thread does something to the value in between the “check” and the “act”. E.g:
if (x == 5) // The "Check"
{
y = x * 2; // The "Act"
// If another thread changed x in between "if (x == 5)" and "y = x * 2" above,
// y will not be equal to 10.
}The point being, y could be 10, or it could be anything, depending on whether another thread changed x in between the check and act. You have no real way of knowing.
In order to prevent race conditions from occurring, you would typically put a lock around the shared data to ensure only one thread can access the data at a time. This would mean something like this:
// Obtain lock for x
if (x == 5)
{
y = x * 2; // Now, nothing can change x until the lock is released.
// Therefore y = 10
}
// release lock for xARM和X86的区别
ARM、x86和x64是计算机领域中常见的处理器架构。它们有以下区别:
ARM架构(Advanced RISC Machine):
- 主要用于移动设备和嵌入式系统,如智能手机、平板电脑、物联网设备等。
- 设计简单,功耗低,适合移动设备的节能需求。
- 32位或64位处理器都有,但大多数ARM处理器仍然是32位的。
- 通常在移动设备中使用的操作系统是基于ARM架构开发的,如Android。
x86架构:
- 主要用于个人电脑和服务器领域。
- 由英特尔(Intel)首先引入,后来被AMD等公司采用。
- 最初是32位处理器,后来发展为64位处理器(x86-64或IA-32e),支持更大的内存地址空间。
- 主流操作系统,如Windows、Linux和macOS,都提供了针对x86架构的版本。
x64架构(也称为AMD64或Intel 64):
- 是x86架构的64位扩展,具有更大的内存寻址空间和更高的性能。
- 支持64位指令集,并且可以运行32位和64位应用程序。
- 在桌面、服务器和高性能计算领域广泛应用。
- 主流操作系统,如Windows、Linux和macOS,都提供了x64架构的版本。
总结来说,ARM架构主要用于移动设备和嵌入式系统,x86架构主要用于个人电脑和服务器,而x64是x86架构的64位扩展,提供更高性能和更大内存寻址空间。
现在ARM在电脑上也有了。
主流的品牌:
以下是当前计算机领域中主流的处理器品牌:
ARM架构:
- Qualcomm(高通):在移动设备市场上非常知名,其Snapdragon系列芯片广泛应用于智能手机和平板电脑。
- Apple:苹果公司自家设计的ARM芯片,如M1芯片用于Mac电脑。
x86架构:
- Intel:英特尔是全球最大的半导体公司之一,其处理器广泛应用于个人电脑、服务器和数据中心。
- AMD:Advanced Micro Devices是另一家知名的处理器制造商,其处理器产品与Intel竞争,在桌面、服务器和游戏领域具有一定市场份额。
需要注意的是,ARM架构主要用于移动设备和嵌入式系统,而x86架构主要用于个人电脑和服务器。在处理器品牌选择时,还应综合考虑性能、功耗、成本和适用场景等因素,以满足特定需求。
机器学习/深度学习
模型、算法、学习之间的关系
- 模型是一个从输入到输出的函数。
- 算法则是利用样本生成模型的方法。
- 学习(也可称为训练)则是利用样本通过算法生成模型的过程。下面举一个大家相对熟悉,而且可能实际操作过的例子:实验数据的线性拟合,一个简单而又经典的机器学习案例。
Benchmark
Benchmark在机器学习中,通常指的是一种对算法、模型或方法性能的标准化评估和比较的方法。衡量和比较不同机器学习算法或模型的表现,以确定哪个方法在特定的任务或数据集上表现最佳。
SLAM
SLAM(Simultaneous Localization And Mapping, 同步定位与地图构建):解决机器人在未知环境运动时的定位和地图构建问题。
Token
Token 是模型处理文本的最小单元。例如:
- 英文文本中,”Hello, world!” 可能被分词为 [“Hello”, “,”, “world”, “!”],共 4 个 token。
- 中文文本中,”你好,世界!” 可能被分词为 [“你”, “好”, “,”, “世界”, “!”],共 5 个 token
Token 与模型性能的关系:
- 上下文窗口:模型的最大 token 数量限制了其处理长文本的能力(如 GPT-4 支持 32,768 tokens)。
- 输出质量:token 数量越多,模型可能生成更详细的内容,但也可能增加幻觉风险(生成不准确信息)。
预测、回归、自回归
按照周志华西瓜书中的说法。
预测包括分类和回归。预测离散变量,那么就是分类问题。如果用来预测连续变量就是回归问题。
在现代统计学中,“回归”指的是一种分析技术,用来确定两个或多个变量间关系的强度和特点。在回归模型中,通常我们基于一个或多个自变量,尝试预测或估计一个因变量。而线性回归,是指自变量和因变量呈线性关系,如下所示:
- Y是因变量,我们要预测的
- X1…Xn是自变量,用于预测Y
是回归系数,表示自变量对因变量的影响强度和方向 是误差项,代表模型未能解释的变异
通过回归分析,我们可以了解变量之间的关系,预测未来的数据,或者对某些行为进行科学的解释。
自回归是一种特殊的回归,是一种处理时序的方法。使用历史时刻的数据作为输入,来预测当前或未来的状态。不是用x来预测y,而是用x预测x(自己),所以称为自回归。
Representation Learning
https://zhuanlan.zhihu.com/p/136554341
表征学习:对原始数据进行提炼,形成特征。
在2013年,Bengio 发表了关于表征学习的综述“Representation learning: A review and new perspectives”
其中有段话如下:
learning representations of the data that make it easier to extract useful information when building classifiers or other predictors
数理
张量
在机器学习等领域,张量就是多维数组。目的是把向量、矩阵推向更高的维度。
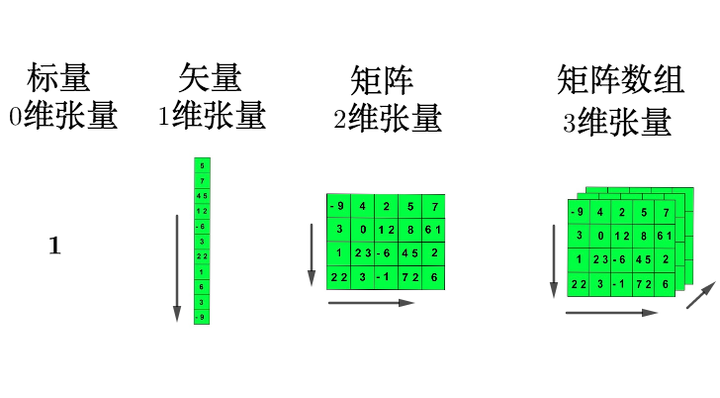
把三维张量画成一个立方体:
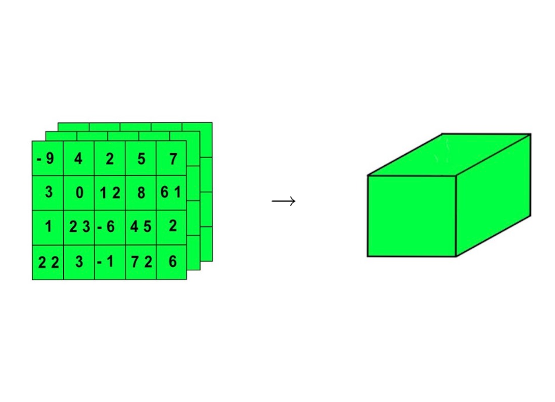
我们就可以进一步画出更高维的张量:
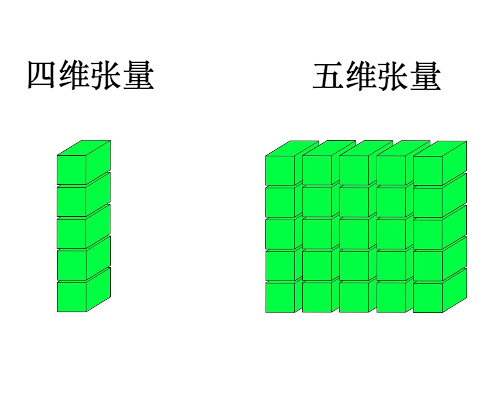
从数据结构上来看,张量就是多维数组。
这个定义本身没有错,但是没有真正反映张量的核心。
测试
MetaData(元数据)
元数据是用来描述数据的数据(Data that describes other data)
年龄(三十岁上下)、身高(个子高挑)、相貌(身材匀称,黑黑的眉毛,红红的脸蛋)、性格(活跃,吵吵嚷嚷,不停地哼着小俄罗斯的抒情歌曲,高声大笑)。有了这些信息,我们就可以大致想像出瓦莲卡是个什么样的人。推而广之,只要提供这几类的信息,我们也可以推测出其他人的样子。
这个例子中的”年龄”、”身高”、”相貌”、”性格”,就是元数据,因为它们是用来描述具体数据/信息的数据/信息。
元数据最大的好处是,它使信息的描述和分类可以实现格式化,从而为机器处理创造了可能。
software stack
软件堆栈是独立组件的集合,这些组件协同工作以支持应用程序的执行。这些组件可能包括操作系统、体系结构层(architectural layers)、协议、运行时环境、数据库和函数调用,它们在层次结构中彼此堆叠在一起。通常,层次结构中的较低级别组件与硬件交互,而层次结构中的较高级别组件为最终用户执行特定任务和服务。组件通过一系列遍历堆栈的复杂指令直接与应用程序通信。

软件堆栈可以很简单,也可以很复杂,具体取决于所需的应用程序功能,并且可以合并来自组织的本地资源、第三方提供商(如 SaaS 供应商)或云提供商提供的组件和服务。
例子
LAMP(Linux,阿帕奇,MySQL,PHP):这是一个众所周知的网络开发软件堆栈。堆栈层次结构的最低层是 Linux 操作系统,它与 Apache Web 服务器接口。层次结构的最高层是脚本语言 - 在本例中为PHP。(“P”也可以代表编程语言Python或Perl。LAMP堆栈很受欢迎,因为这些组件都是开源的,并且堆栈可以在商用硬件上运行。与通常紧密耦合且通常针对特定操作系统构建的整体式软件堆栈不同,LAMP堆栈是松散耦合的。这仅仅意味着,虽然这些组件最初不是为协同工作而设计的,但它们已被证明是互补的,并且经常一起使用。今天,LAMP组件现在都包含在几乎所有的Linux发行版中。开发人员可以将 MySQL 换成后格雷SQL 来创建缆普堆栈。LEAP 堆栈(Linux、桉树、AppScale、Python)是此开源软件堆栈的另一种风格,用于基于云的开发和服务交付。
MEAN(MongoDB,Express,Angular,Node.js):这一堆开发工具有助于消除软件开发中经常遇到的语言障碍。平均堆栈的基础是蒙哥DB,一个NoSQL文档数据存储。HTTP 服务器是快速的,而角度是前端 JavaScript 的框架。堆栈的最高层是 Node,它是服务器端脚本的平台。请注意,MEAN不依赖于特定的操作系统,这为开发人员提供了更大的灵活性;它还使用JavaScript,这是一种无处不在的编程语言。开发人员可以使用余烬而不是角度,这创建了一个MEEN堆栈;或者使用 Vue.js作为 MEVN 堆栈中的前端开发框架。
Benchmark
原链接)
Benchmark:基准测试
基准测试旨在模拟组件或系统上特定类型的工作负载。综合基准测试通过专门创建的程序来实现这一点,这些程序将工作负载强加给组件。应用程序基准测试在系统上运行实际程序。虽然应用程序基准测试通常可以更好地衡量给定系统上的实际性能,但综合基准测试对于测试单个组件(如硬盘或网络设备)非常有用。
基准测试在 CPU 设计中尤为重要,它使处理器架构师能够在微架构决策中进行测量和权衡。例如,如果基准测试提取应用程序的关键算法,它将包含该应用程序的性能敏感方面。在周期精确的模拟器上运行这个小得多的代码段可以提供有关如何提高性能的线索。
容器
CRI
CRI (Container Runtime Interface) consists of a specifications/requirements (to-be-added), protobuf API, and libraries for container runtimes to integrate with kubelet on a node.



