现阶段通信模型
数据封装过程
- 应用层:生成用户数据(如HTTP请求、FTP文件、DNS查询等),通过Socket接口与传输层交互。数据直接传递给传输层,无需添加头部(部分协议如HTTP可能包含应用层头部)。
- 示例:用户在浏览器输入 https://www.example.com,生成HTTP请求数据。
- 传输层:添加TCP头部:源端口(随机端口如50000) + 目的端口(443)。TCP:建立连接(三次握手)、数据确认、流量控制、拥塞控制。
- 示例:将HTTP请求数据分割为多个TCP段(Segment),每个段添加TCP头部(源端口80、目标端口55000等)。
- 网络层:添加IP地址(源IP和目标IP),实现跨网络路由。根据路由表选择最佳路径。
- 示例:源IP地址为 192.168.1.10,目标IP地址为 93.184.216.34(通过DNS解析获得)。
- 链路层:将IP数据包封装为以太网帧(Frame),添加MAC地址(源MAC和目标MAC)。通过ARP协议解析目标IP对应的MAC地址。
- 示例:源MAC地址为 00:1A:2B:3C:4D:5E,目标MAC地址为下一跳路由器的MAC地址(如 00:0D:3C:4E:5F:6A)。
- 物理层:将帧转换为比特流(0/1序列),通过物理介质(如网线、光纤)传输。
数据传输
数据从发送端出发后,经过交换机和路由器等设备,逐层处理。
交换机/路由器接收到的是物理信号(电信号/光信号),需先转换为数字比特流。比特流被组装成数据帧,设备检查帧完整性。
交换机:读取帧头的目标MAC地址,查询MAC地址表,决定转发端口(不修改IP层内容)
路由器:解析IP头部,根据路由表选择下一跳。修改IP头部的TTL(生存时间)字段。
重新封装为新的以太网帧(目标MAC地址为下一跳设备的MAC地址)。
数据包可能经过多个路由器,每台路由器根据路由表选择下一跳,最终跳转至目标网络所在的子网。
数据解封装
到达后,进行解封装:物理层 → 数据链路层(校验帧)→ 网络层(匹配IP)→ 传输层(TCP/UDP端口)→ 应用层
通信模型发展历史
原文链接:有了 IP 地址,为什么还要用 MAC 地址? - 涛叔的回答 - 知乎
https://www.zhihu.com/question/21546408/answer/2120115071
点对点链路
最早的网络是「猫」+电话线。一台电脑接一个猫,连一条电话线。理论上只要完成拨号,双方就能进行通信。
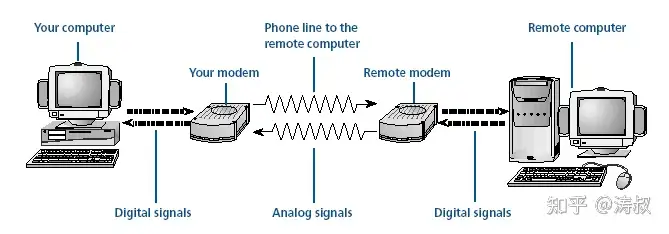
为是一条电话线的两头,这边电脑发出的所有信号自然会被另一端的电脑收到。所以不需要给双方指定 MAC 地址或者 IP 地址之类东西。
Mesh拓扑
点对点链路的优点是简单清晰,但缺点也很明显——不支持连接多台电脑。如果你想连多台电脑,就需要给电脑配置多个猫。如果有多台电脑需要相互连接,就需要每台的电脑的每个猫都连到一起。这样做不但成本很高,管理负担也非常重。这种连接方式叫全网状(Full Mesh)拓朴网络。
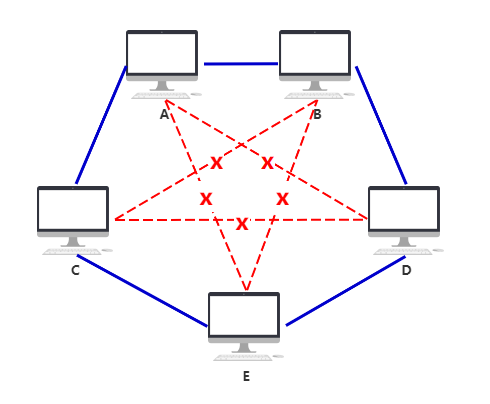
Mesh网络也不是一无是处,它最大的优点就是可靠性高。网络中的部分链接出现故障不会影响到整个网络。但成本高,维护困难的缺点真是抗不住。
成本高归高,计算机之间还是以点对点的方式进行通信。所以这类网络本质上跟第一种点对点链路没有区别。设备之间的通信也不需要设置 MAC 或 IP。
总线网络
为了降低成本,人们想了另外一种连接方式,总线网线。
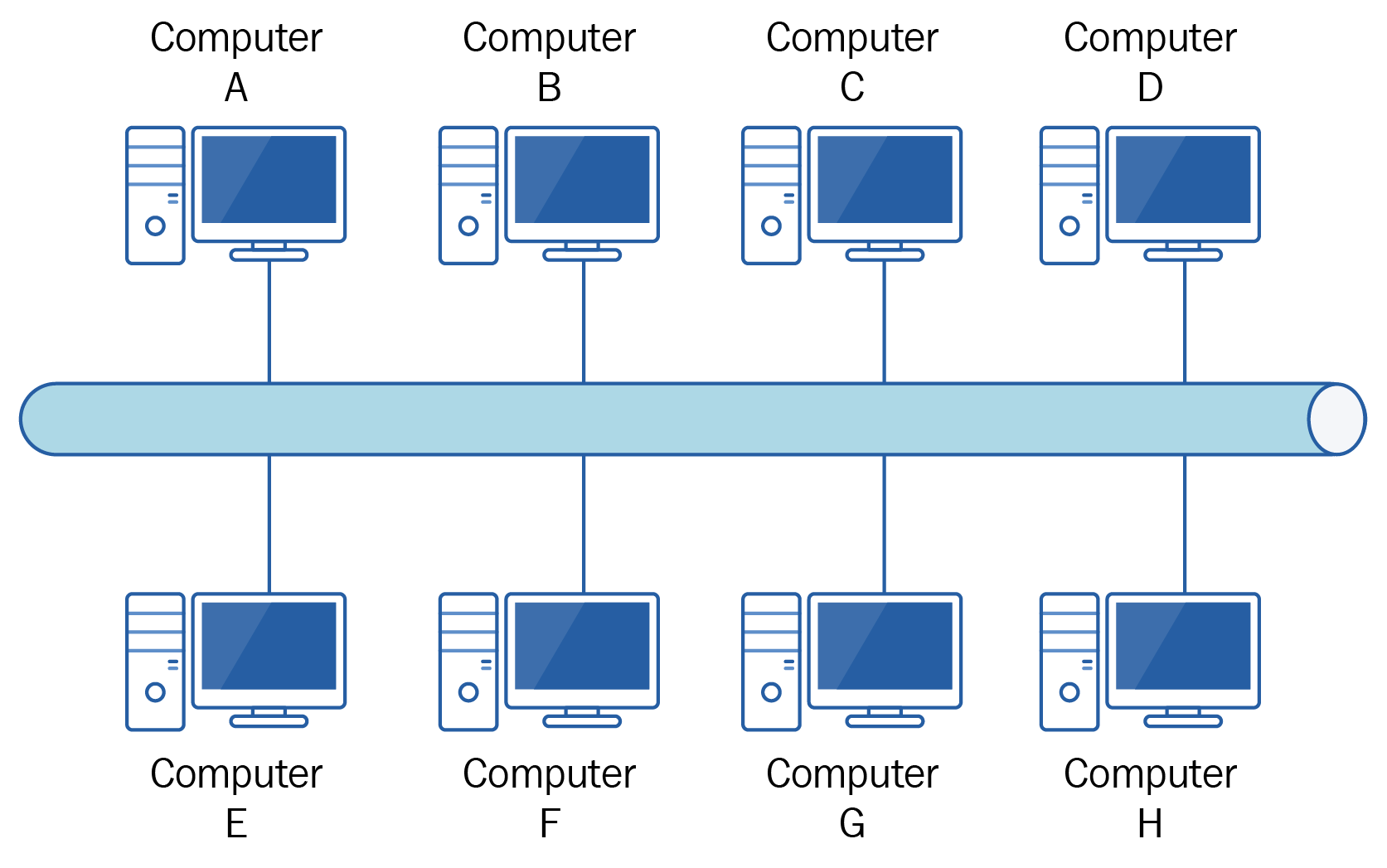
之所以成本低,是因为所有的电脑只需要接一个猫,然后所有猫接到同一条网线上(叫总线,早期使用的是同轴电缆)。
组网成本确实降低了,但使用成本却上升了。如果上图中A想给B发数据,可以启动自己的猫开始发送。如果此时C也给D发数据,那就会形成干扰,最终谁的数据也发不出来。为了解决这个问题,人们规定,如果想发数据,必须先使用自己的猫「听」一下网线上有没有其他电脑正在通信。如果有,就自觉等待一段时间,然后再检查。这套机制后来演化了成载波侦听多路访问/碰撞检测(CSMA/CD)机制。教科书上都会讲这个CSMA/CD。
MAC地址
解决了冲突问题,总线网络就能工作吗?不能!我们在前面讲的点对点链路两边各有一台电脑,收发双方非常明确,不需要指定MAC或者IP。但在总线网络中,所有电脑共享一条电缆,可以同时接收网络上的全部信号。那大家怎么确定数据是发给自己的呢?
为了解决这个问题,人们发明了数据帧的概念。帧是发送数据的最小单位。当时是用很多链接层协议,以太网只是后面设计的一种。但不同的帧结构大同小异,核心都包含目标地址、源地址和数据三部分。
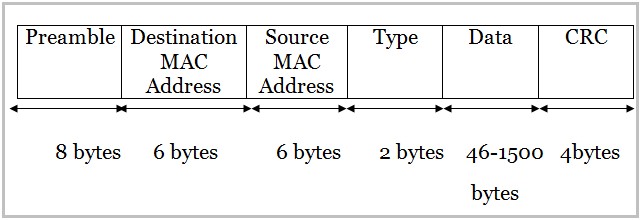
这里首次出现了地址这个概念。正是因为总线网线中所有设备共享总线,所以需要通过引入地址的概念来区分不同的设备。对于以太网,这个地址就是我们常说的MAC地址。这个时候的「猫」就已经变成了我们现在常说的网卡了。以太网规定MAC地址占6个字节,也就前面说的48位。
网桥
随着总线网络的普及,越来越多的大公司或组织(主要是大学)开始使用网络连接它们的设备。为了方便传输数据,人们还发明了网桥。可以把网桥想象成装有多个网卡的设备,每个网卡连接一个总线网络。网桥唯一的作用就是把从一个网卡收到的内容原样转发到另一张网卡所在的网络。
MAC地址的局限
但是随着网络的规模越来越大,连网的设备越来越多,通信冲突的频率也越来越高。最终的结果就是数据传输的速度越来越低(因为只要有一人在发数据,其他所有人都得等待)。但就这样,人们对互联互通的要求还没有被满足。人们发现路由(也就是寻找数据包从发送方到接收方的路径)变得越来越困难了。于是人们想了一个办法,就是把网络划分成很多个子网。这样,在路由的时候,路由器可以把其他子网看成一个整体来进行计算。对于目的地在其他子网的数据包,路由器只需要让数据包到达那个子网即可,而剩下的工作就由子网内部解决了。虽然这种方法只能让寻找到的路径接近最优而不保证最优,不过它大大减少了路由器的计算量,利大于弊,所以被采用了。
那么为什么我们需要 IP 地址呢?因为如果我们只用 MAC 地址的话,我们会发现路由器需要记住每个 MAC 地址所在的子网是哪一个(不然每一次收到数据包的时候路由器都要重新满世界地去找这个 MAC 地址的位置)。而世界上有
并且MAC地址是厂商固化在硬件上的,不能随意编辑。小规模通信没问题,但是可扩展性很差。无法有效的对MAC地址进行分组和聚合。
IP地址
后来想了一个办法,就是让网桥变的智能一点。让它可以「学习」不同网络所有设备的MAC地址。当有数据需要转发的时候,它可以根据目标地址判断应该转发到哪个网卡,从而减少广播的数量。
但是,因为以太网的MAC是在出厂的时候指定的,所以没有一个简单的办法确定某个总线网络中的所有MAC地址,只能通过广播来学习,也只能在网桥设备保存全部的MAC地址,而且还要及时更新。
最终,另一拨人(IETF)想出了再加一层的方案,也就是在以太网上引入了网络层(也就是IP层)。注意,网络层是IETF这拨人鼓捣出来的,以太网是IEEE那拨人鼓捣出来的。IETF这拨人决定给每一台网络设备加一个逻辑地址,也就是IP地址,而且觉得32位差不多够用了,甚至都没考虑 MAC 地址是48位。
引了IP协议层,前面说的网络问题基本得到解决。
路由
首先,每一台设备都有一个IP地址。通信双方使用IP地址进行通信。IP地址是管理员按需指定的,可以根据前缀聚合。所以原来的网桥(现在变成了路由器)不需要保存网络中的所有MAC地址,只要保存网络前缀就能进行转发。
但问题来了,网络层工作在链路层之上。要想通信,还得需要MAC地址。怎样才能得到目标的MAC地址呢?这就需要用到ARP协议。
ARP协议
在各个设备里面,有一张ARP缓存表,记录着IP与MAC地址的对应关系。
一开始的时候这个表是空的,电脑 A 为了知道电脑 B(192.168.0.2)的 MAC 地址,将会广播一条 arp 请求,B 收到请求后,带上自己的 MAC 地址给 A 一个响应。此时 A 便更新了自己的 arp 表。
这样通过大家不断广播 arp 请求,最终所有电脑里面都将 arp 缓存表更新完整。
交换机
先有路由器,再有交换机。
交换机到现在更多是解决路由器网线口有限的问题



