知识蒸馏
知识蒸馏是对模型的能力进行迁移,将一个大模型(教师模型)在经可能保证其预测效果的前提下压缩为一个小模型(学生模型)。
知识蒸馏的核心是:知识、蒸馏算法、师生架构
按照知识来说,可以分为:基于Logits/响应、基于特征、基于关系。
蒸馏的方式也有:离线蒸馏、在线蒸馏、自蒸馏
下面以离线蒸馏、基于Logits为样例,解释知识蒸馏的流程。
训练阶段
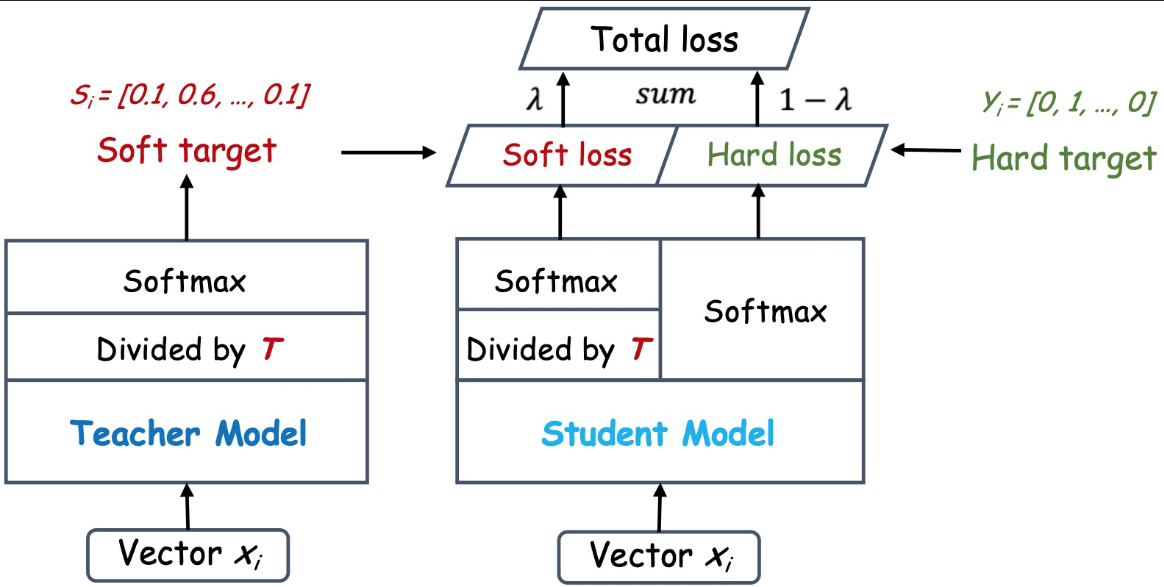
教师模型和学生模型的输入都是相同的。
分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。但是知识蒸馏过程中会进行一个“温度挑战”输出概率分布:
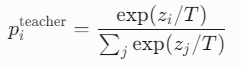
就是每个概率除以”T”。
学生模型的输出也通过相同的温度缩放,以匹配教师模型的分布。
学生模型的LOSS由两部分组成,一部分是蒸馏损失,另一部分是监督损失。总LOSS是两部分的加权和,参数
为什么需要温度参数T
能增强学生模型的泛化能力
上面这句话是相比于使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型
原因是:
- 传统的Hard-target的训练方式,所有的负标签都会被平等对待。Soft-target给Student模型带来的信息量要大于Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。
- 使用Soft-target训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。
T越大,Softmax的输出就会越加平缓,信息熵越大。
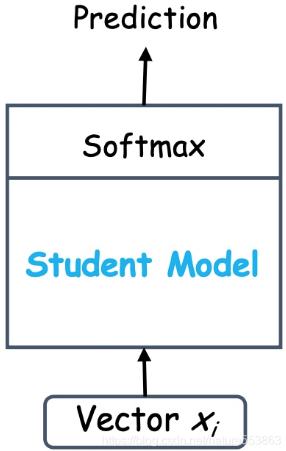
推理阶段
学生模型在推理时移除温度参数(就是令T=1),直接输出原始概率分布。
基于特征的知识
和”基于响应/Logit的知识“不同,基于特征的知识就是把教师模型中间层的特征作为知识,让学生模型学习。
具体来说,中间层就是除开输入层和输出层,特征就是每一层的输出。
因为教师和学生模型架构不一样,维度/通道数等可能不一样,为了对齐特征,需要一个对齐操作。比如卷积层/全连接层,或者上/下采样等。
FitNets(FITNETS: HINTS FOR THIN DEEP NETS)是在学生模型架构中加入卷积层/全连接层来解决维度问题。

基于关系的知识
什么是蒸馏算法
蒸馏算法的本质是通过设计损失函数和训练策略,将教师的知识转化为学生可学习的信号
熵
熵
熵是信息论中的一个概念,用来衡量一个随机事件的 不确定性 或 混乱程度。熵越高,说明事件的不确定性越大;熵越低,说明事件越确定。
其中:
是事件 发生的概率 - 对数底数通常取2(单位为比特)或自然对数 e(单位为纳特)
例子:抛硬币
如果一枚均匀硬币(正反面概率各50%),熵为:
交叉熵
交叉熵用于衡量 两个概率分布之间的差异,交叉熵的值越大,说明两个分布差异越大。
其中:
- 真实分布为 p,模型预测分布为 q
例子:分类问题中的预测
假设一个二分类问题(如“猫”或“狗”),真实标签是“猫”(概率1),模型预测结果为:
这说明预测较准确,交叉熵较小。
如果模型预测“猫”的概率为0.1,交叉熵为:2.302
这说明预测错误,交叉熵较大。
所以,使用交叉熵作为损失函数,在预测错误时较大,正确时较小,避免了均方误差的梯度消失问题
熵和交叉熵的关系
交叉熵可以拆分为熵和相对熵(KL散度)之和:
其中:
是真实分布的熵。 是相对熵(KL散度),当且仅当 p=q 时为0。
传统知识蒸馏损失函数
传统知识蒸馏损失函数如下:



