无监督训练流程
无监督训练和有监督训练的区别在于没有标签,数据不需要提前标注。之所以采用无监督训练,是因为异常检测领域中异常数据往往是很少的。如果采用有监督训练,那么会优先学习正常数据的分布,就无法识别异常。
采用无监督训练,一种常见的策略是重建。我们这里以设备监控为例,一台设备在100个连续时刻采集了5个传感器的数据,这样的数据为一个样本。一共采集10个这样的数据。输入维度为(10,100,5)
模型的输出是重构后的时序数据,与原始的数据比较后,计算Loss,反向传播更新参数。设定阈值,假设超过阈值的就是异常,就判定哪个时刻,哪个传感器的值是异常的。
无监督和自监督的区别
深度学习中,自监督(self-supervised)和无监督(unsupervised)有什么区别? - Zarathustra的回答 - 知乎
https://www.zhihu.com/question/329202439/answer/2786160932
自监督学习与无监督学习,这二者就是一样的
性能度量
(本部分出自西瓜书)
衡量模型泛化能力的评价标准,被称为性能度量(performance measure)。回归任务常用的性能度量均方误差,而分类任务中常用的是错误率和精度。
错误率和精度
错误率是分类错误的样本占总样本的比例,精度是分类正确的占比。
查准率、查全率和F1
错误率和精度虽常用,但并不能满足所有任务。以西瓜问题为例,假定瓜农拉来一车西瓜,用模型判别西瓜。错误率衡量了有多少比例的瓜被误判。但若我们关系的是“挑出的西瓜有多少比例是好瓜”,或者“所有好瓜中有多少比例被挑出来了”,那么错误率就不够用。
类似的需求在信息检索、Web搜索等应用中,我们经常关心“检索出的信息中有多少比例是用户感兴趣的” “用户感兴趣的信息中有多少被检索出来了”。查准率(precision)与查全率(recall)是更适合此类需求的性能度量。
查准率也被称为准确率,查全率也称为召回率。
二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为四个结果,分类结果的混淆矩阵如下:
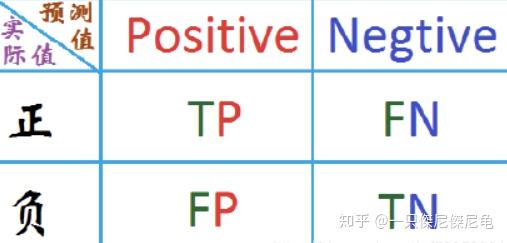
Positive/Negative 表示的预测结果,前面的True/False表示预测的结果是否为真。
- True Positive(真正, TP):预测正样本正确
- True Negative(真负 , TN):预测负样本正确
- False Positive(假正, FP):预测正样本错误
- False Negative(假负 , FN):预测负样本错误
查准率P定义:TP / (TP + FP)
查全率R定义:TP / (TP + FN)
查全率和查准率是一对矛盾的度量。例如,若希望将好瓜尽可能选出来,可以通过增加选瓜的数量来实现。如果选上所有的瓜,所有的好瓜肯定都被选上,但是这样查准率会降低;如果希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,但难免漏掉不少好瓜,查全率低。
P-R曲线
在很多情形下,我们根据预测结果对样例进行排序,排在最前面的是学习器认为“最可能”是正例的样本,排在最后的则是学习器认为“最不可能”是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查准率、查全率。以查准率为纵轴,查全率为横轴,就能得到查准率-查全率曲线,简称P-R曲线。
举个例子来计算P-R曲线:
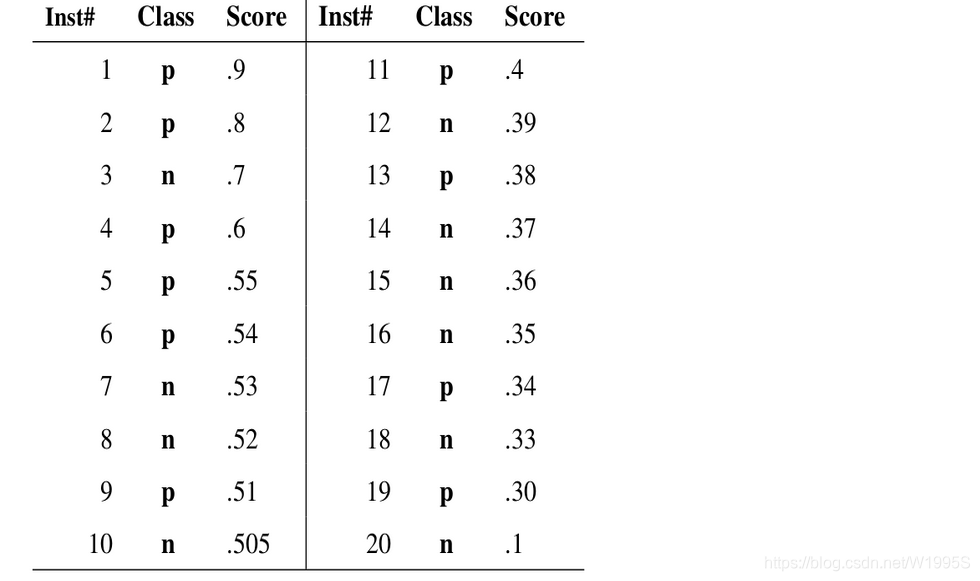
如上图: 真实情况正例反例各有10个。 先用分数score=0.9作为阈值(大于等于0.9为正例,小于0.9为反例),此时TP=1,FP=0,FN=9,故根据Precision/Recall公式,P=1,R=0.1。 用0.8作为阈值,P=1,R=0.2。 用0.7作为阈值,P=0.67,R=0.2。 用0.6作为阈值,P=0.75,R=0.3。 以此类推。(下面的图是示意图,不对应上面数据)
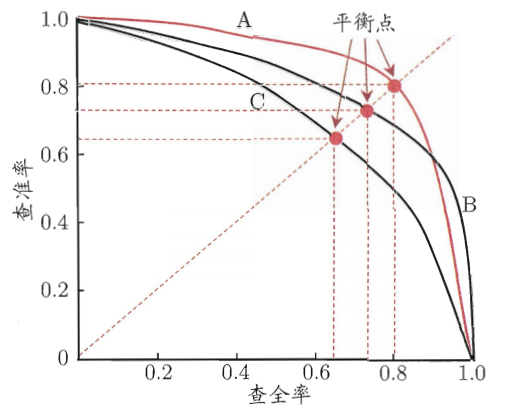
P-R 曲线越靠近右上角性能越好
进行比较时,若一个学习器的P-R曲线被另一个全部包围,那么后者性能优于前者。例如上图中的A优于C。如果发生交叉,一般难以直接断言孰优孰劣。如果一定要比较,可以比较P-R曲线下的面积,但是这个值不太容易估算,因此有了综合考虑查准率和查全率的度量。
F1度量
当
ROC与AUC
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,用于衡量学习器的泛化性能。
纵轴是“真正例率”(TPR),横轴是”假正例率“(FPR)
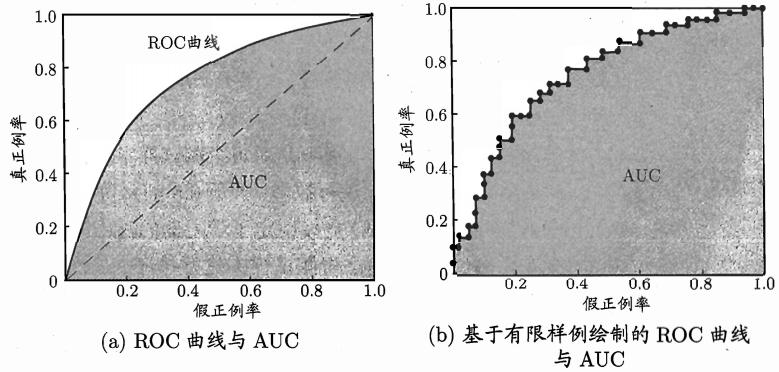
现实任务中通常是利用有限个测试样例来绘制ROC图,无法产生图a那样的光滑曲线,只能绘制出图b那样近似曲线。
进行学习器比较时,与P-R图类似,一个学习器的ROC被另一个包围,那么后者的性能更好。若发生交叉,一定要进行比较,可以比较ROC曲线下的面积,即AUC(Area Under ROC Curve)。
假定ROC曲线是由坐标为
为什么在异常样本较少时,大多采用无监督而非有监督
有监督学习为什么不行
核心问题:损失函数设计
有监督依赖交叉熵损失函数优化,目的是最大化正确分类的概率(学习正常和异常的边界)。当异常样本极少时(如占比1%以下),损失函数会被正常样本主导,导致模型偏向预测所有样本为正常类别。无法学习异常特征。

模型直接学习“将所有样本预测为正常”的简单策略,准确率可能高达99%,但对异常完全无效。
无监督的策略
无监督方法(如自编码器)通过重构正常数据分布检测异常,其核心逻辑与有监督完全不同:
无监督对正常数据进行密度估计;数学本质是概率密度函数;
如果任务是重构,那么训练目标就是最小化预测结果和输入的差异。

无监督仅仅优化正常样本的重构误差,模型专注于正常样本的分布,只要偏离正常分布,异常自然检测到。
传统无监督存在的问题
如果采用基本的MSE作为loss函数,因为正常数据量太大,导致被正常样本主导,可能过拟合。如果正常样本周围出现噪声,那么有可能因为重构误差大而被判定为异常。
还有一种可能是MSE只从”点“的角度评估,忽略了时序的关联性。比如心跳具有周期性,单点值可能是正常的,但是异常房颤表现为周期紊乱,可能无法捕捉周期性异常。
一般提高准确率通常会导致召回率下降,反之亦然
总样本:1000
异常样本(Positive):10
正常样本(Negative):990
如果模型将所有样本都预测为正常(Negative)
TP:0 (没有检测到任何异常)
FN:10 (所有异常都被漏检)
FP:0 (没有误报)
TN:990 (所有正常样本都被识别)
召回率就是0,精确率因为分母也为0,没有意义。实际上可能有少数是误报的。
显示关联建模(Explicit Association Modeling)
直接定义和量化时间序列内部或不同变量之间的关联关系来进行异常检测的方法。这类方法的核心是人为设定或数学化描述变量间的相互作用模式(如线性关系、状态转移、图连接等),而非依赖神经网络等黑箱模型隐式学习关联。
典型方法有:向量自回归、状态空间模型、基于图的方法
与隐式关联建模(如深度学习相比),显示关联建模可解释性高、计算成本低。但是不适用非线性关系场景。
尽管显式方法在复杂场景中被神经网络取代,但其思想仍被借鉴:
图神经网络(GNN):
结合显式图结构与隐式特征学习,如用Transformer建模时空图(如STGNN)。
可解释性AI:
在神经网络中引入显式关联约束(如稀疏注意力、因果掩码),增强可解释性。
混合建模:
用VAR捕捉线性趋势,用LSTM拟合非线性残差,提升预测鲁棒性。
时序异常检测
异常定义
异常可以分为:点异常、局部异常、序列异常
点异常
点异常可以是单变量异常,也可以是多变量异常。
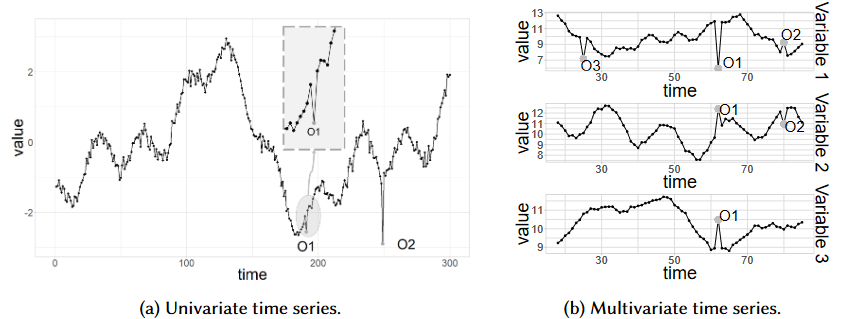
单变量异常:在一个时间序列变量中,某个时间点的值明显偏离了它周围大部分数据点。
多变量异常:在多变量场景中,任何一个变量单独看,其数值可能都在它自己的合理范围内。但是,当把这些变量在同一个时间点的值组合起来看时,它们之间的关系或组合模式却是不正常的、意外的。
比如上图中的(b):
- 变量1 (Var1):在O1时刻,它是一个局部低谷。但如果只看Var1这个曲线,这个低谷的深度和它之前的一些波动相比,似乎并不算特别离谱,它自己不足以被判为异常。
- 变量2 (Var2):在O1时刻,它有一个波动偏离。同样,单独看Var2,这个波动也可能在它的正常波动范围内。
- 变量3 (Var3):在O1时刻,它是一个短暂的峰值。单独看Var3,这个峰值也许很突出,但如果没有其他信息,我们可能会以为这只是Var3自己的一个正常波动。
正常情况下,这三个变量之间存在某种“默契”或“协定”。例如:
- 可能 Var1 下降时,Var2 通常会上升,Var3 保持平稳。
- 或者 Var3 出现峰值时,Var1 和 Var2 必须同时达到某个阈值。
而在 O1 这个时刻,这三个值的组合模式(Var1低谷 + Var2波动 + Var3峰值) 违反了它们之间历史数据所建立起来的正常关系模式。是这个“组合”出问题了
举个例子:
多变量数据就是一个人的体检报告,每个变量就是一项指标(心率、血压、血糖)。
- 单变量异常:你的心率是200次/分钟(正常60-100)。光这一项就能断定你身体异常了。
- 多变量异常:你的体检报告显示:
- 心率:85 (正常)
- 血压:120/80 (正常)
- 血糖:140mg/dL (轻微偏高,但可能在正常值边缘)
单独看任何一项,都在正常或临界范围。 但是,一个经验丰富的医生看到这个组合会警觉起来:“一个心率正常、血压正常的人,在非餐后时间血糖不应该无缘无故达到这个值,这组指标之间的关系不太对劲”,从而判断可能存在潜在健康风险。这个“风险”就是多变量异常。



