所遇问题
Matplotlib 中文乱码
https://zhuanlan.zhihu.com/p/30790786209
对于大多数情况生效的最快的解决方法,将下面这一段加入到代码的头部。
# 设置全局字体为 SimHei (黑体) 或其他中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 或 ['Microsoft YaHei'] 微软雅黑 等
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题为什么会出现中文乱码?
Matplotlib 默认使用的字体是英文字体,字库中不包含中文字符,因此在绘制包含中文的图表元素(如标题、坐标轴标签、图例等)时,就会出现乱码。
解决方案总览
我们将介绍以下几种解决方案,建议按顺序尝试,选择最适合你的方法:
方法一:代码中临时指定字体(最常用、推荐) - 简单快捷,适用于大多数情况。
方法二:手动指定字体路径(灵活控制) - 适用于需要自定义字体或跨平台部署的情况。
如果你想使用特定的字体文件(例如,从网上下载的字体),或者需要更精细地控制字体设置,可以使用 FontProperties 手动指定字体路径。
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 1. 下载字体文件 (例如 SimHei.ttf) 并放置在你的项目目录下或系统字体目录
# 2. 创建 FontProperties 对象,指定字体文件路径和大小
font_path = 'SimHei.ttf' # 替换为你的字体文件路径 (可以是相对路径或绝对路径)
font = FontProperties(fname=font_path, size=14)
# 示例代码
x = [1, 2, 3, 4, 5]
y = [2, 4, 1, 3, 5]
plt.plot(x, y)
plt.title('折线图示例 - 中文标题', fontproperties=font) # 应用于标题
plt.xlabel('X 轴 - 横轴', fontproperties=font) # 应用于 X 轴标签
plt.ylabel('Y 轴 - 纵轴', fontproperties=font) # 应用于 Y 轴标签
plt.legend(['数据系列 - 中文图例'], prop=font) # 应用于图例 (使用 prop 参数)
plt.show()- 方法三:修改 Matplotlib 配置文件(永久生效) - 一劳永逸,但需谨慎操作。
如果你希望一劳永逸地解决所有 Matplotlib 图表的中文乱码问题,可以修改 Matplotlib 的配置文件 matplotlibrc。请谨慎操作,修改配置文件可能影响所有使用 Matplotlib 的项目。
- 操作系统特殊处理 - 针对 Windows、Mac/Linux 和 Google Colab/Jupyter 环境的特殊字体设置。
输出格式有问题
背景:python2.7,IDE:VSCode
源码:
two.txt: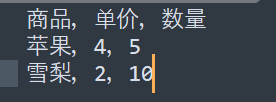
输出:
预期应该为商品,单价,数量。
修改最后一行的print
打包pip install 包
背景:内网需要安装python和一些包,无法连互联网,只能外网下载再u盘拷过去。
在外网机器Python的安装目录中新建一个文件夹,如packages:
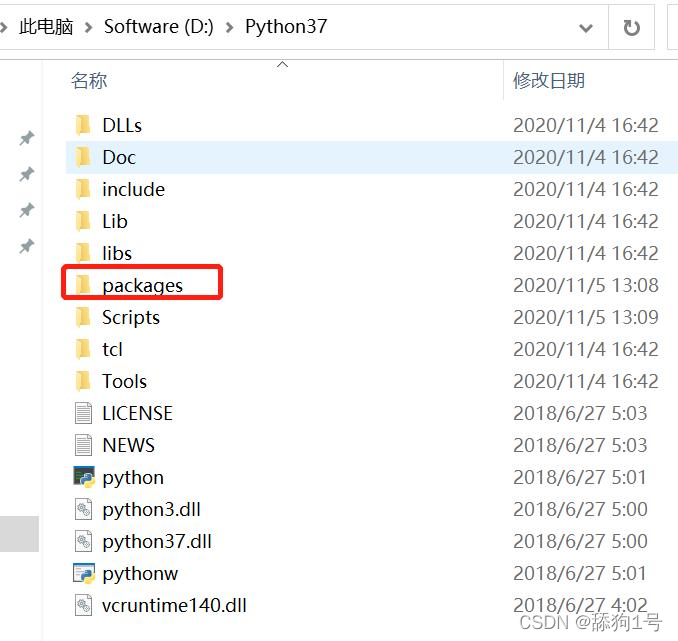
进入到packages文件夹下,shift按住,鼠标右键“在此处打开命令行”,输入pip
list查看系统中安装了哪些python包,如下: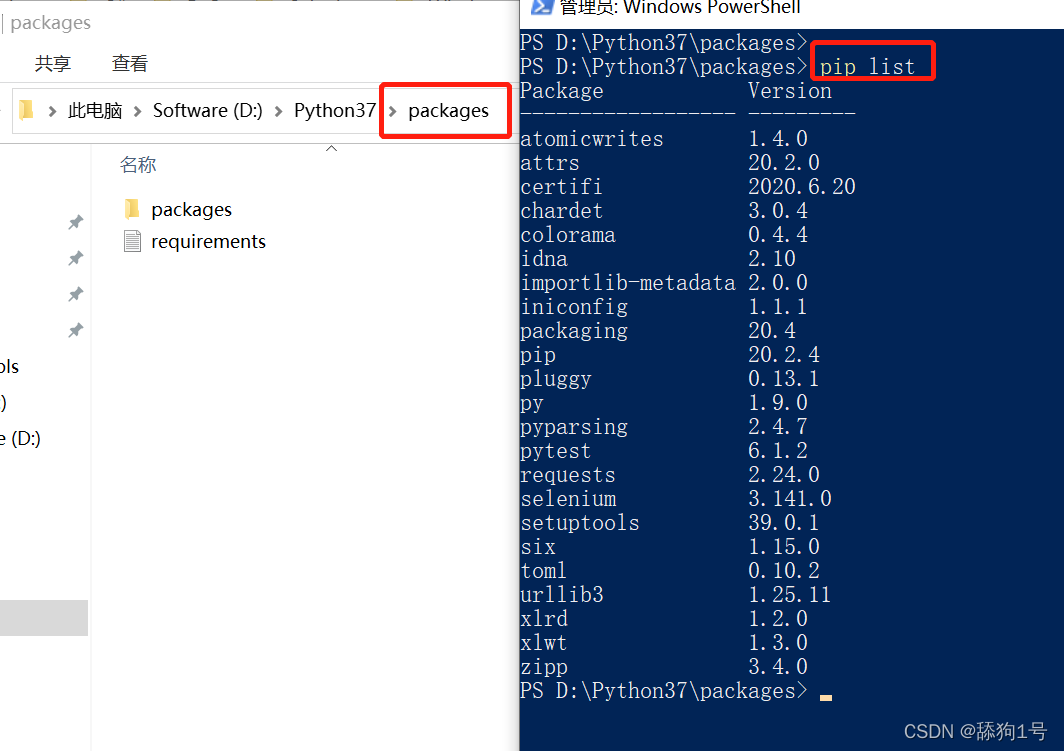
- 把所有包名及版本号,重定向到requirements.txt中
pip freeze >requirements.txt - 然后下载系统中已经安装的所有包到一个目录下,比如在packages的packages中,使用如下命令,此时packages下有两个文件:
pip download -r requirements.txt -d packages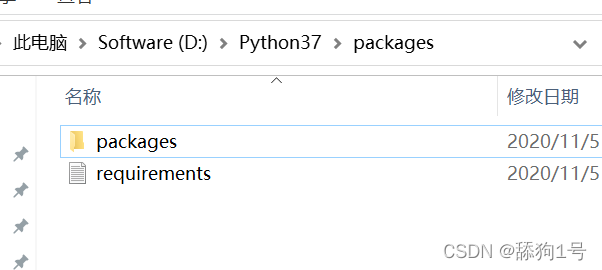
- 内网安装。先复制刚才外网机器上的文件夹pacjages到内网机器对应的目录
- 进入到D:\Python37\packages下,打开命令行,执行安装
pip install --no-index --find-links=packages -r requirements.txt 如果失败,可以一个一个安装
pip install XXXX包名python2.7 卸载失败问题
背景:使用.msi文件进行卸载,出现以下情况:
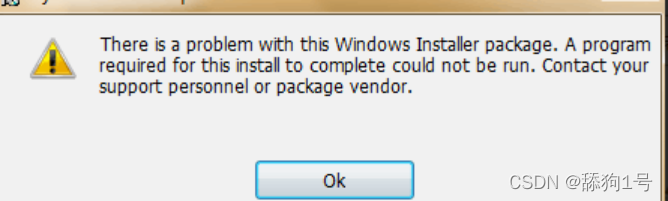
解决方法:
找到出问题的版本,个人当时出问题的版本是2.7.10。官网下载msi文件。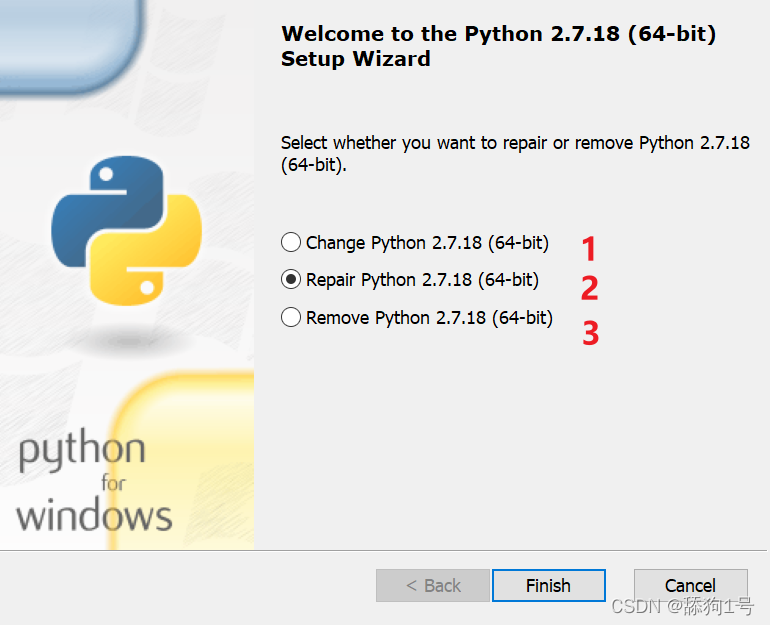
依次运行。
open函数传参数出错
背景:python2.7,open函数传递参数。
自定义函数,函数里面调用open函数

如果不在路径前面加r,就会报错。按理说应该是
open(file_path,mode)
后面写出函数,拼接的时候老出错。
解决办法:
路径使用/
‘C:/Users/76585/Desktop/compare/one.txt’
open函数可以正常使用open(path,mode)
Python编码错误的解决办法SyntaxError: Non-ASCII character ‘\xe5’ in file
原因:python的默认编码文件是用的ASCII码,而你的python文件中使用了中文等非英语字符
解决办法:
在Python源文件的最开始一行,加入一句:
##coding=UTF-8(等号换为”:“也可以)或者
##-*- coding:UTF-8 -*-RuntimeError: dictionary changed size during iteration
在字典遍历过程中修改字典元素,报错 RuntimeError: dictionary changed size during iteration
得知遍历时不能修改字典元素
for k in func_dict.keys():
if func_dict[k] is np.nan:
del func_dict[k]
continue解决办法:将遍历条件改为列表
for k in list(func_dict.keys()):
if func_dict[k] is np.nan:
del func_dict[k]
continueVScode code runner无法运行出正确的结果
背景:
内网电脑上,通过python程序对文件进行读写操作,但是没有出现相应的结果。单步调试可以出正确的结果。
分析:
通过print 输出可以发现问题。命令行运行py文件可以得到正确的结果,说明原因出在code runner上面。
解决办法:
1.首选项找到设置
2.输入code-runner,找到 Executor Map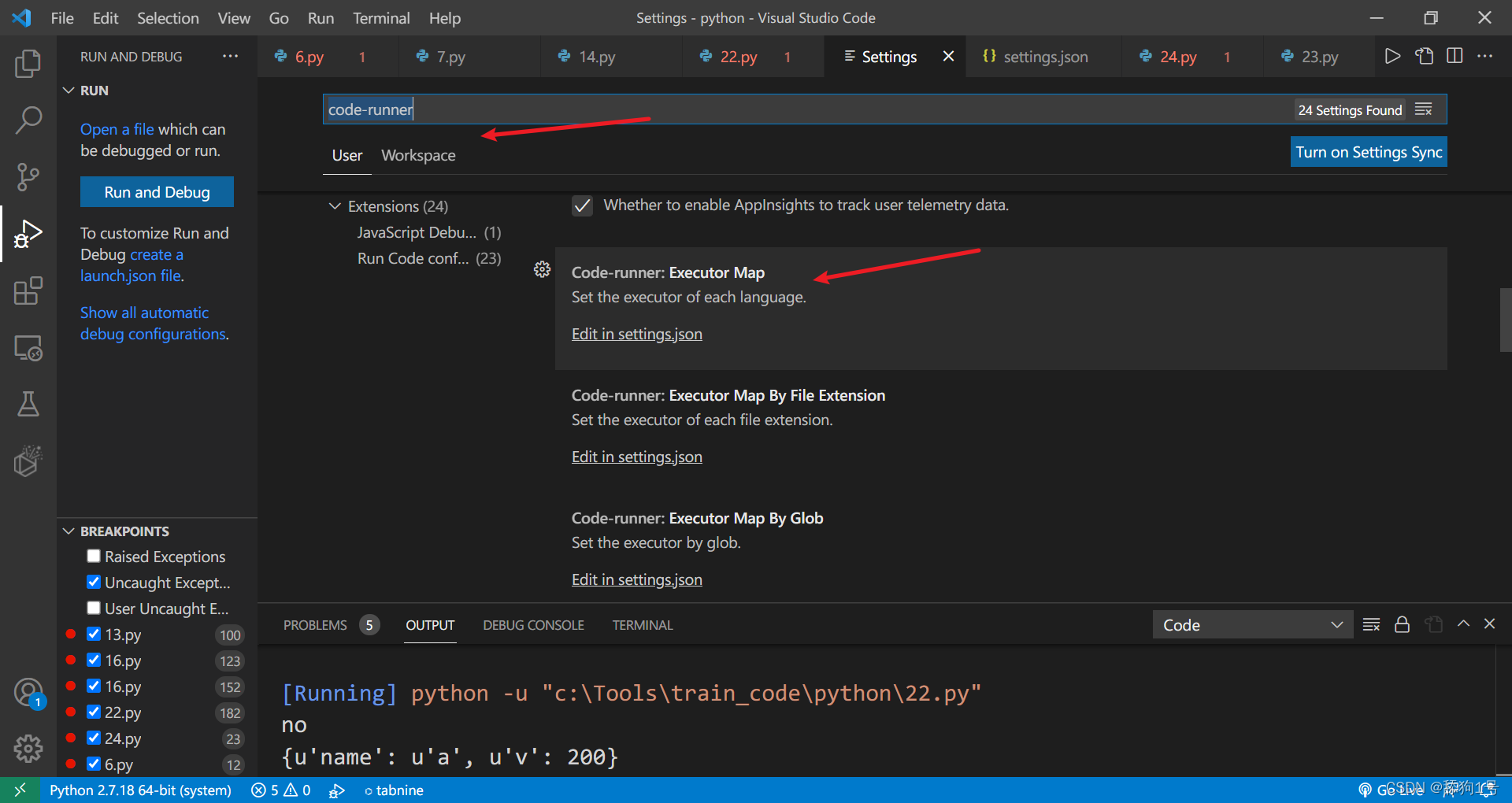
3.选择这个,(将设置复制为id)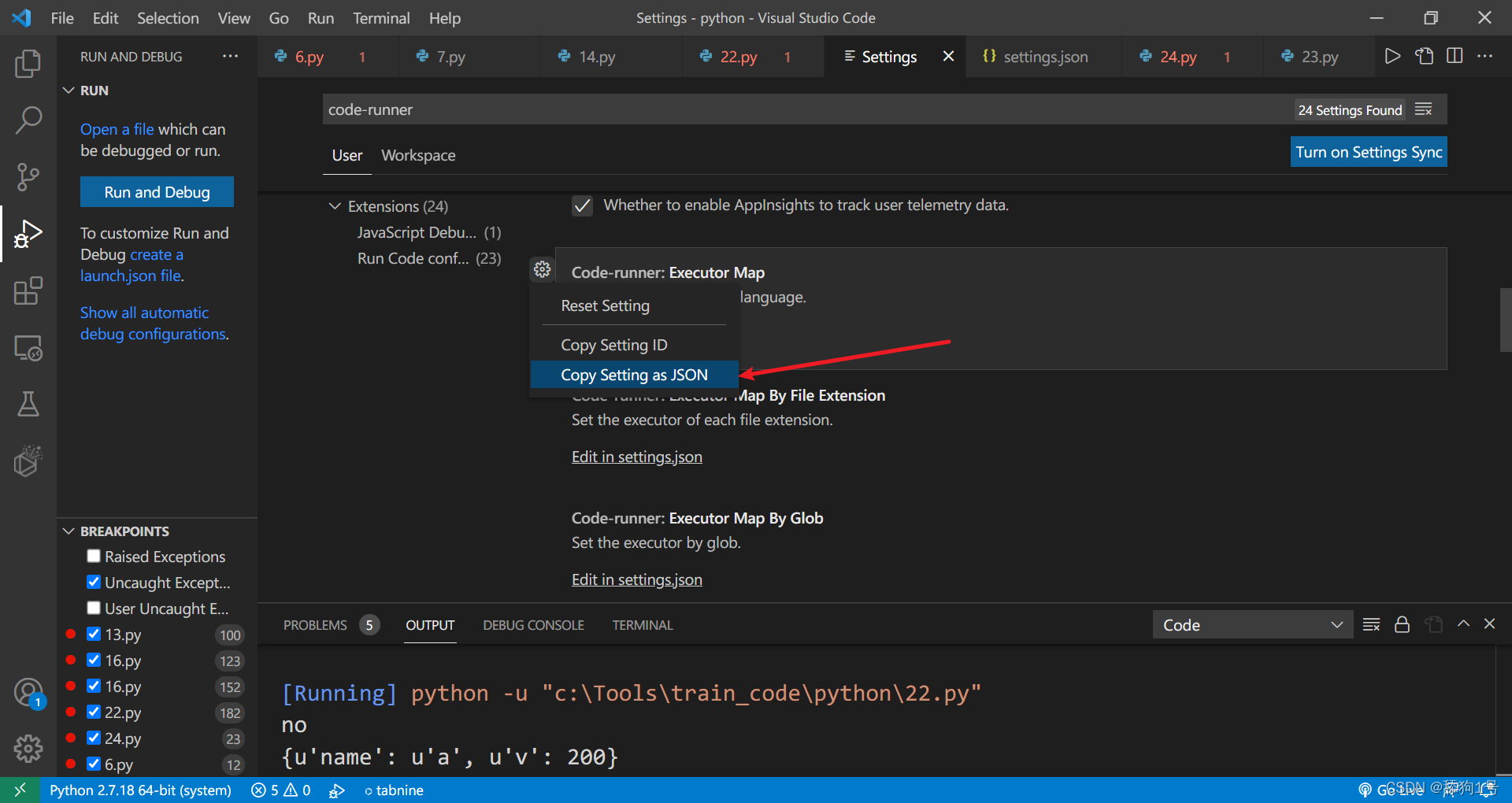
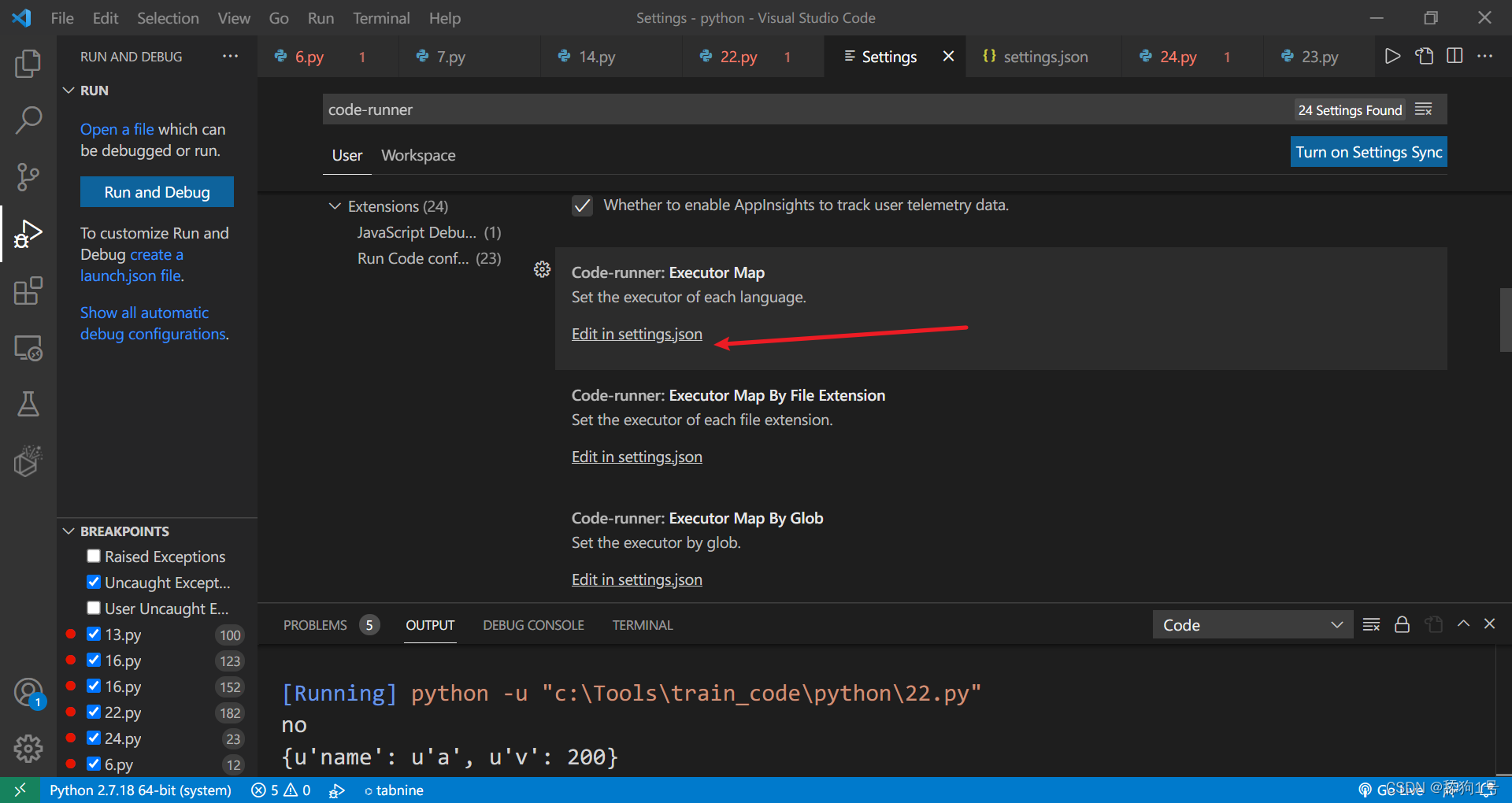
将复制的内容粘贴到里面
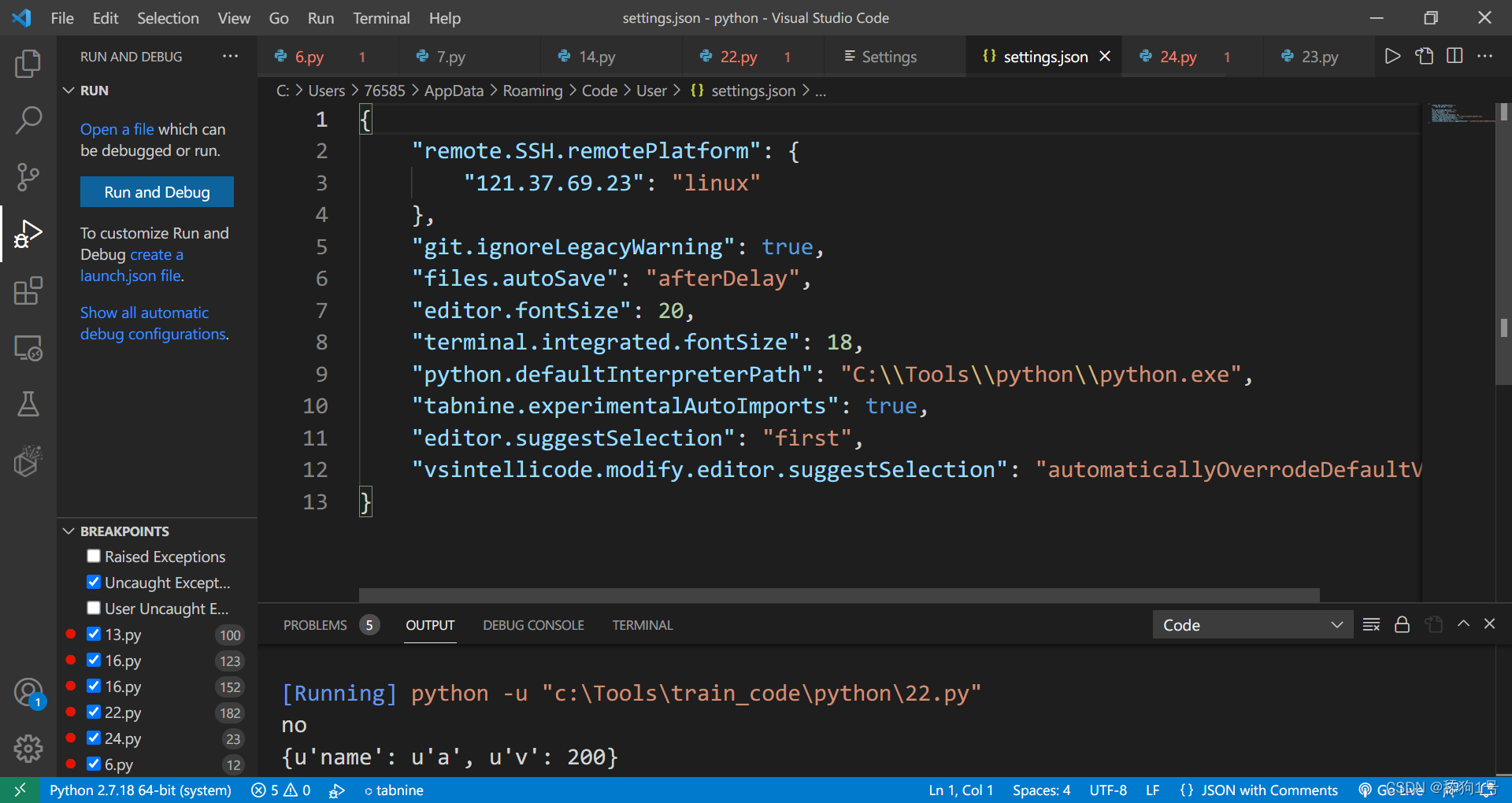
修改其中python字段的python值替换为vscode左下角的python解释器:
结果如下;
"python": "C:\\Python27\\python.exe -u" //注意转义符
//下面这个也可以
"python": "\"C:/Python27/python.exe\" -u"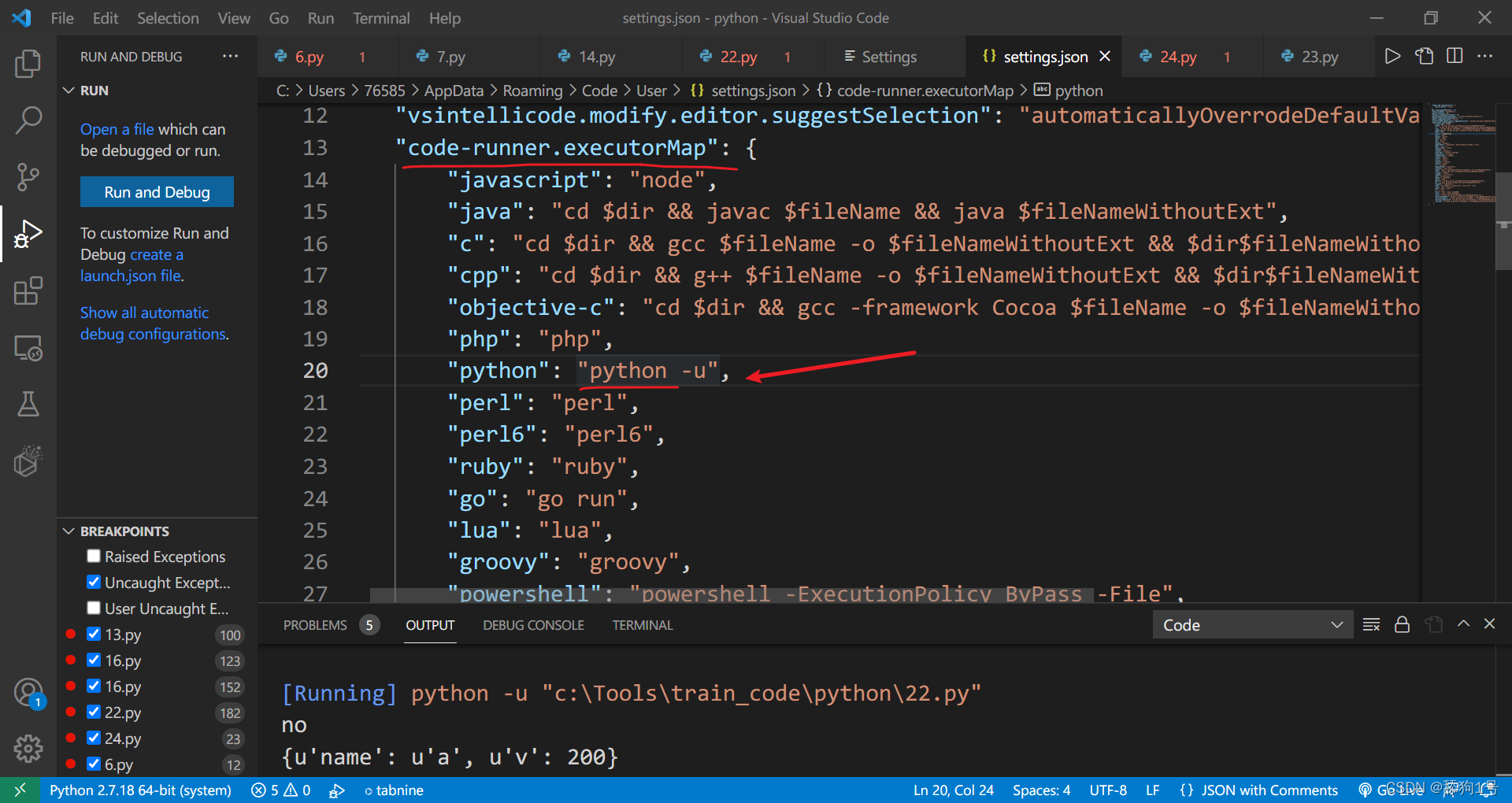
vscode进行调试,系统把conda activate base写入了用户输入区域该怎么办?
问题:在运行调试的时候编译器在运行语句前没有进入虚拟base环境,于是在遇到激活用户输入语句时,自动输入了conda activate base ,导致程序出错
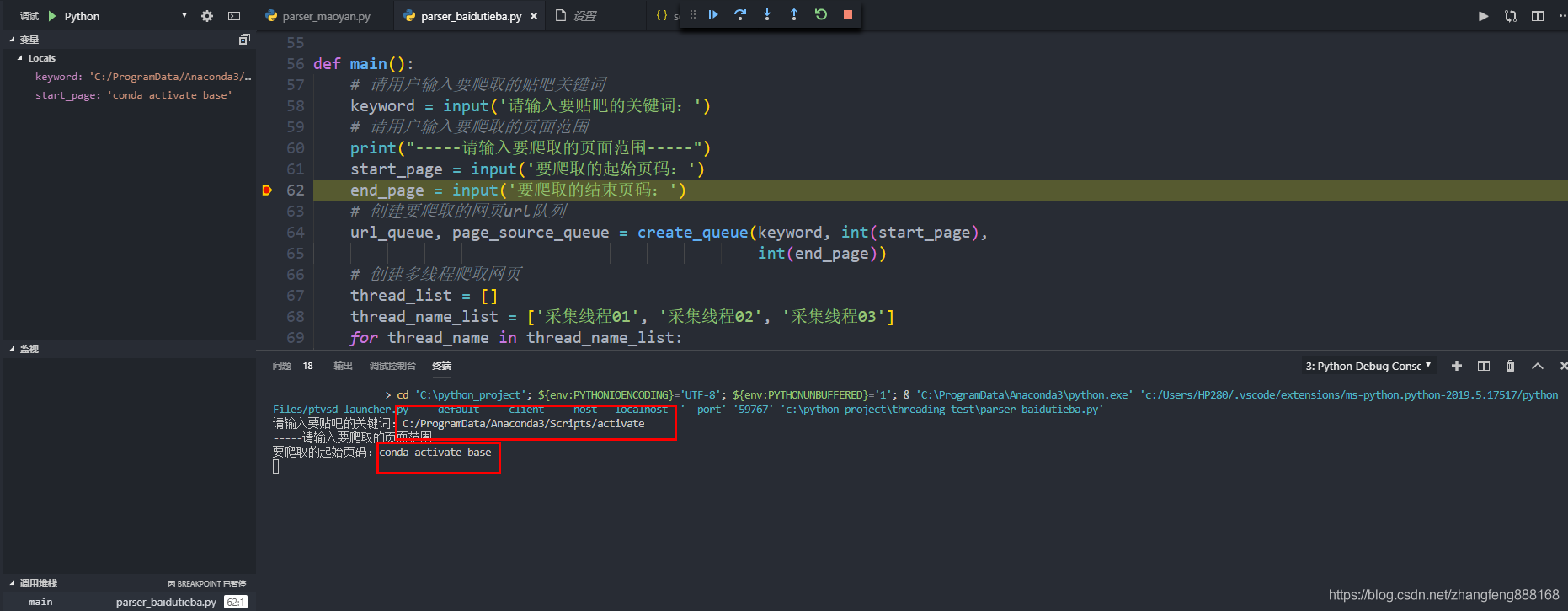
解决办法:避免在使用这些终端命令时激活虚拟环境和conda环境,请将python.terminal.activateEnvironment设置更改为false
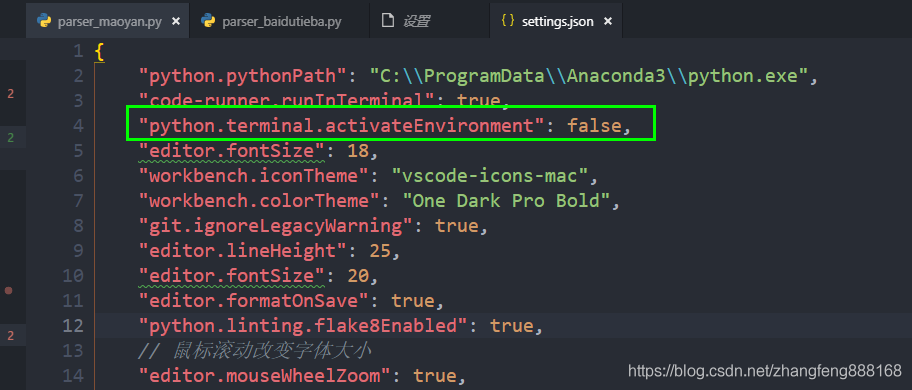
这个setting.json在在C:\Users\Administrator\AppData\Roaming\Code\User\setting.json 是个纯文本文件,直接打开就好。如果没有python.terminal.activateEnvironment这一行可以自己加上。
windows安装了conda,但无法在vscode使用

cmd可以正常使用,环境变量也添加了,但是一直不行。
解决办法:
找到conda安装目录下的Scripts下的activate,在vscode终端输入命令激活:
C:\Users\76585\Miniconda3\Scripts\activatewindows安装多版本python,如何指定pip
不适用conda的情况下,安装多个版本python,把环境变量设置好以后,可以通过修改exe程序的名字来区分,默认都是python.exe,可以修改为python311.exe或python39.exe,
如果要使用对应版本的pip,可以这样做
python37 -m pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simpleConda环境下无法正常使用mpi或mpi4py
首先理解下关于mpi的一些知识,mpi是一个概念,和SSH类似。
OpenMPI 和 MPICH 是两种不同的 MPI(Message Passing Interface)实现,而 mpicc 和 mpirun 是 MPI 编译器和运行时工具。
如果系统上安装了,那么输入which mpicc或者which mpirun是能够找到这两个可执行程序的路径。如果没有启动Conda环境,那么一般是在/usr/bin目录下;如果启动了Conda环境,那么一般是在这种目录下:/home/zhpe/anaconda3/envs/lgf-py310-pyfr/bin/
如果Conda环境下,输出这两个都没问题,那么可以接着用mpicc --version和mpirun --version看看
我当时使用mpicc --version报错了,信息如下:
The Open MPI wrapper compiler was unable to find the specified compiler
x86_64-conda_cos6-linux-gnu-cc in your PATH.
Note that this compiler was either specified at configure time or in
one of several possible environment variables.
解决的方法是,把系统的gcc拷贝到该Conda环境的bin目录下,然后改名为x86_64-conda_cos6-linux-gnu-cc。
启动Conda环境,会优先在该Conda环境下的bin和lib目录下去找可执行程序和库文件。假如你还是想调用系统的东西,那么做法就是在Conda环境下,设置环境变量,export PATH=/usr/bin:$PATH,上面的命令是临时的,关闭shell后就没了。
我当时报的错是:
ImportError: /home/zhpe/anaconda3/envs/lgf-py310-pyfr/lib/python3.10/site-packages/mpi4py/MPI.cpython-310-x86_64-linux-gnu.so: undefined symbol: MPI_UNWEIGHTED
用pip卸载mpi4py重新安装还是不行,后面尝试了一种方法成果了:
pip uninstall mpi4py
pip install --no-cache-dir mpi4py—no-cache-dir 是 pip 的一个选项,它告诉 pip 在安装过程中不使用本地缓存来存储包。这意味着,pip 会每次都从远程源(比如 PyPI)重新下载包,而不会使用本地缓存中可能已经存在的包版本。
关于上面的gcc编译器的问题,也不确定如果不设置编译器的情况下使用pip install —no-cache-dir mpi4py能否成功。
技术知识点
遍历文件夹下的文件名
方法1:使用os.listdir
import os
for filename in os.listdir(r'c:\windows'):
print("文件夹名字",filename)方法2:使用glob模块,可以设置文件过滤
import glob
for filename in glob.glob(r'c:\windows\*.exe'):
print("是.exe的文件名",filename)方法3:非递归
import os
for dirpath, dirnames, filenames in os.walk('D:'):
print('文件路径', dirpath)
print('文件夹名字',dirnames)
for filename in filenames:
print('文件名', filename)sorted排序
案例:
文件夹里面的文件按照文件名里面的数字进行排序
文件如下:0.txt, 1.txt, 2.txt, 3.txt, 34.txt, 54.txt …………….
file_list=os.listdir(file_path)
file_list.sort(key=lambda x:int((re.findall(r'\d+', str(x)))[0]))1.re.findall(r’\d+’, str(x))[0] 正则表达式提取数字,但结果是列表,所以把元素取出来,再用一个int转成整数类型
按照key来排序,后面是一个lambda表达式。
对列表排序,返回的对象不会改变原列表
list = [1,5,7,2,4]
sorted(list)
Out[87]: [1, 2, 4, 5, 7]
##可以设定时候排序方式,默认从小到大,设定reverse = False 可以从大到小
sorted(list,reverse=False)
Out[88]: [1, 2, 4, 5, 7]
sorted(list,reverse=True)
Out[89]: [7, 5, 4, 2, 1]根据自定义规则来排序,使用参数:key
## 使用key,默认搭配lambda函数使用
sorted(chars,key=lambda x:len(x))
Out[92]: ['a', 'is', 'boy', 'bruce', 'handsome']
sorted(chars,key=lambda x:len(x),reverse= True)
Out[93]: ['handsome', 'bruce', 'boy', 'is', 'a']根据自定义规则来排序,对元组构成的列表进行排序
tuple_list = [('A', 1,5), ('B', 3,2), ('C', 2,6)]
##key=lambda x: x[1]中可以任意选定x中可选的位置进行排序
sorted(tuple_list, key=lambda x: x[1])
Out[94]: [('A', 1, 5), ('C', 2, 6), ('B', 3, 2)]
sorted(tuple_list, key=lambda x: x[0])
Out[95]: [('A', 1, 5), ('B', 3, 2), ('C', 2, 6)]
sorted(tuple_list, key=lambda x: x[2])
Out[96]: [('B', 3, 2), ('A', 1, 5), ('C', 2, 6)]排序的元素是自定义类
class tuple_list:
def __init__(self, one, two, three):
self.one = one
self.two = two
self.three = three
def __repr__(self):
return repr((self.one, self.two, self.three))
tuple_list_ = [tuple_list('A', 1,5), tuple_list('B', 3,2), tuple_list('C', 2,6)]
sorted(tuple_list_, key=lambda x: x.one)
Out[104]: [('A', 1, 5), ('B', 3, 2), ('C', 2, 6)]
sorted(tuple_list_, key=lambda x: x.two)
Out[105]: [('A', 1, 5), ('C', 2, 6), ('B', 3, 2)]
sorted(tuple_list_, key=lambda x: x.three)
Out[106]: [('B', 3, 2), ('A', 1, 5), ('C', 2, 6)]根据多个字段来排序
class tuple_list:
def __init__(self, one, two, three):
self.one = one
self.two = two
self.three = three
def __repr__(self):
return repr((self.one, self.two, self.three))
tuple_list_ = [tuple_list('C', 1,5), tuple_list('A', 3,2), tuple_list('C', 2,6)]
## 首先根据one的位置来排序,然后根据two的位置来排序
sorted(tuple_list_, key=lambda x:(x.one, x.two))
Out[112]: [('A', 3, 2), ('C', 1, 5), ('C', 2, 6)]二维排序
>>>l=[('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
>>>sorted(l, key=lambda x:x[0])
Out[39]: [('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
>>>sorted(l, key=lambda x:x[0], reverse=True)
Out[40]: [('e', 3), ('d', 4), ('c', 6), ('b', 2), ('a', 1)]
>>>sorted(l, key=lambda x:x[1])
Out[41]: [('a', 1), ('b', 2), ('e', 3), ('d', 4), ('c', 6)]
>>>sorted(l, key=lambda x:x[1], reverse=True)
Out[42]: [('c', 6), ('d', 4), ('e', 3), ('b', 2), ('a', 1)]字符串操作
字符串切割
注:使用前需要引入包(import re)
功能:split能够按照所能匹配的字串将字符串进行切分,返回切分后的字符串列表
形式:
re.split(pattern, string[, maxsplit=0, flags=0])pattern:匹配的字符串
string:需要切分的字符串
maxsplit:分隔次数,默认为0(即不限次数)
flags:标志位,用于控制正则表达式的匹配方式,比如:是否区分大小写,,,如下图所示
具体分析:
//传入某个文件的绝对路径(file_path),根据 '\'进行分割,将结果存入列表,再取出最后一个,就是文件名。
new_line= re.split(r'[/]',str(file_path))
file_name=new_line[-1]替换字符串中的匹配项
re.sub()
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)从上面的代码中可以看到re.sub()方法中含有5个参数,下面进行一一说明(加粗的为必须参数):
(1)pattern:该参数表示正则中的模式字符串;
(2)repl:该参数表示要替换的字符串(即匹配到pattern后替换为repl),也可以是个函数;
(3)string:该参数表示要被处理(查找替换)的原始字符串;
(4)count:可选参数,表示是要替换的最大次数,而且必须是非负整数,该参数默认为0,即所有的匹配都会被替换;
(5)flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
使用案例:
1.匹配单一数字
(1)只匹配单一数字
>>> import re
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[0-9]', '*', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m ** years old. Today is ****/**/**. It is a wonderful DAY! @HHHHello,,,#***ComeHere***...**?AA?zz?——http://welcome.cn"
上面 re.sub(r’[0-9]’, ‘*’, s) 这句话则表示只匹配单一数字,并将每一个数字替换为一个星号 。
(2)只匹配单一字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[a-z]', '*', s)
"大家好,我是一个程序员小白。I '* ** **** ** ********* ******, *** I’* 18 ***** ***. T**** ** 2020/01/01. I* ** * ********* DAY! @HHHH****,,,#111C***H***222...66?AA?**?——****://*******.**"
>>> re.sub(r'[A-Z]', '*', s)
"大家好,我是一个程序员小白。* 'm so glad to introduce myself, and *’m 18 years old. *oday is 2020/01/01. *t is a wonderful ***! @****ello,,,#111*ome*ere222...66?**?zz?——http://welcome.cn"
>>> re.sub(r'[A-Za-z]', '*', s)
"大家好,我是一个程序员小白。* '* ** **** ** ********* ******, *** *’* 18 ***** ***. ***** ** 2020/01/01. ** ** * ********* ***! @********,,,#111********222...66?**?**?——****://*******.**"上面 re.sub(r’[a-z]’, ‘‘, s) 这句话则表示只匹配单一小写字母,并将每一个小写字母替换为一个星号 。
上面 re.sub(r’[A-Z]’, ‘‘, s) 这句话则表示只匹配单一大写字母,并将每一个大写字母替换为一个星号 。
上面 re.sub(r’[A-Za-z]’, ‘*’, s) 这句话则表示只匹配单一字母,并将每一个字母替换为一个星号 。
(3)匹配单一数字和字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[0-9A-Z]', '*', s)
"大家好,我是一个程序员小白。* 'm so glad to introduce myself, and *’m ** years old. *oday is ****/**/**. *t is a wonderful ***! @****ello,,,#****ome*ere***...**?**?zz?——http://welcome.cn"
>>> re.sub(r'[0-9a-z]', '*', s)
"大家好,我是一个程序员小白。I '* ** **** ** ********* ******, *** I’* ** ***** ***. T**** ** ****/**/**. I* ** * ********* DAY! @HHHH****,,,#***C***H******...**?AA?**?——****://*******.**"
>>> re.sub(r'[0-9A-Za-z]', '*', s)
"大家好,我是一个程序员小白。* '* ** **** ** ********* ******, *** *’* ** ***** ***. ***** ** ****/**/**. ** ** * ********* ***! @********,,,#**************...**?**?**?——****://*******.**"上面 re.sub(r’[0-9A-Z]’, ‘‘, s) 这句话则表示只匹配单一数字和大写字母,并将每一个数字和大写字母替换为一个星号 。
上面 re.sub(r’[0-9a-z]’, ‘‘, s) 这句话则表示只匹配单一数字和小写字母,并将每一个数字和小写字母替换为一个星号 。
上面 re.sub(r’[0-9A-Za-z]’, ‘*’, s) 这句话则表示只匹配单一数字和字母,并将每一个数字和字母替换为一个星号 。
2.匹配多个数字或字母
注意:这里的所说的多个指的是大于等于一个。
(1)匹配多个数字
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[0-9]+', '*', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m * years old. Today is */*/*. It is a wonderful DAY! @HHHHello,,,#*ComeHere*...*?AA?zz?——http://welcome.cn"上面 re.sub(r’[0-9]+’, ‘*’, s) 这句话则表示匹配多个连续的数字,并将多个连续的数字替换为一个星号 。
(2)匹配多个字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[a-z]+', '*', s)
"大家好,我是一个程序员小白。I '* * * * * *, * I’* 18 * *. T* * 2020/01/01. I* * * * DAY! @HHHH*,,,#111C*H*222...66?AA?*?——*://*.*"
>>> re.sub(r'[A-Z]+', '*', s)
"大家好,我是一个程序员小白。* 'm so glad to introduce myself, and *’m 18 years old. *oday is 2020/01/01. *t is a wonderful *! @*ello,,,#111*ome*ere222...66?*?zz?——http://welcome.cn"
>>> re.sub(r'[a-zA-Z]+', '*', s)
"大家好,我是一个程序员小白。* '* * * * * *, * *’* 18 * *. * * 2020/01/01. * * * * *! @*,,,#111*222...66?*?*?——*://*.*"上面 re.sub(r’[a-z]+’, ‘‘, s) 这句话则表示匹配多个连续的小写字母,并将多个连续的小写字母替换为一个星号 。
上面 re.sub(r’[A-Z]+’, ‘‘, s) 这句话则表示匹配多个连续的大写字母,并将多个连续的大写字母替换为一个星号 。
上面 re.sub(r’[A-Za-z]+’, ‘*’, s) 这句话则表示匹配多个连续的字母,并将多个连续的字母替换为一个星号 。
(3)匹配多个数字和字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[0-9a-zA-Z]+', '*', s)
"大家好,我是一个程序员小白。* '* * * * * *, * *’* * * *. * * */*/*. * * * * *! @*,,,#*...*?*?*?——*://*.*"上面 re.sub(r’[0-9A-Za-z]+’, ‘*’, s) 这句话则表示匹配多个连续的数字和字母,并将多个连续的数字、连续的字母、连续的数字和字母替换为一个星号 。
3.匹配其他
(1)匹配非数字
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[^0-9]', '*', s)
'********************************************************18***********************2020*01*01**************************************111********222***66**************************'
>>> re.sub(r'[^0-9]+', '*', s)
'*18*2020*01*01*111*222*66*'上面 re.sub(r’0-9‘, ‘‘, s) 这句话则表示匹配单个非数字,并将单个非数字替换为一个星号 。
上面 re.sub(r’0-9+’, ‘‘, s) 这句话则表示匹配多个连续的非数字,并将多个连续的非数字替换为一个星号 。
(2)匹配非字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[^a-z]', '*', s)
'*****************m*so*glad*to*introduce*myself**and***m****years*old*****oday*is**************t*is*a*wonderful***********ello********ome*ere************zz***http***welcome*cn'
>>> re.sub(r'[^A-Z]', '*', s)
'**************I*************************************I*******************T********************I*****************DAY***HHHH***********C***H************AA***********************'
>>> re.sub(r'[^A-Za-z]', '*', s)
'**************I**m*so*glad*to*introduce*myself**and*I*m****years*old****Today*is*************It*is*a*wonderful*DAY***HHHHello*******ComeHere*********AA*zz***http***welcome*cn'
>>> re.sub(r'[^a-z]+', '*', s)
'*m*so*glad*to*introduce*myself*and*m*years*old*oday*is*t*is*a*wonderful*ello*ome*ere*zz*http*welcome*cn'
>>> re.sub(r'[^A-Z]+', '*', s)
'*I*I*T*I*DAY*HHHH*C*H*AA*'
>>> re.sub(r'[^A-Za-z]+', '*', s)
'*I*m*so*glad*to*introduce*myself*and*I*m*years*old*Today*is*It*is*a*wonderful*DAY*HHHHello*ComeHere*AA*zz*http*welcome*cn'上面 re.sub(r’a-z‘, ‘‘, s) 这句话则表示匹配单个非小写字母,并将单个非小写字母替换为一个星号 。
上面 re.sub(r’A-Z‘, ‘‘, s) 这句话则表示匹配单个非大写字母,并将单个非大写字母替换为一个星号 。
上面 re.sub(r’A-Za-z‘, ‘‘, s) 这句话则表示匹配单个非字母,并将单个非字母替换为一个星号 。
上面 re.sub(r’a-z+’, ‘‘, s) 这句话则表示匹配多个连续的非小写字母,并将多个连续的非小写字母替换为一个星号 。
上面 re.sub(r’A-Z+’, ‘‘, s) 这句话则表示匹配多个连续的非大写字母,并将多个连续的非大写字母替换为一个星号 。
上面 re.sub(r’A-Za-z+’, ‘‘, s) 这句话则表示匹配多个连续的非字母,并将多个连续的非字母替换为一个星号 。
(3)匹配非数字和非字母
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[^0-9A-Za-z]', '*', s)
'**************I**m*so*glad*to*introduce*myself**and*I*m*18*years*old****Today*is*2020*01*01**It*is*a*wonderful*DAY***HHHHello****111ComeHere222***66*AA*zz***http***welcome*cn'
>>> re.sub(r'[^0-9A-Za-z]+', '*', s)
'*I*m*so*glad*to*introduce*myself*and*I*m*18*years*old*Today*is*2020*01*01*It*is*a*wonderful*DAY*HHHHello*111ComeHere222*66*AA*zz*http*welcome*cn'上面 re.sub(r’0-9A-Za-z‘, ‘‘, s) 这句话则表示匹配单个非数字和非字母,并将单个非数字和非字母替换为一个星号 。
上面 re.sub(r’0-9A-Za-z+’, ‘‘, s) 这句话则表示匹配多个连续的非数字和非字母,并将多个连续的非数字和非字母替换为一个星号 。
(4)匹配固定形式
a.只保留字母和空格,将 repl 设置为空字符即可。
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[^a-z ]', '', s)
' m so glad to introduce myself and m years old oday is t is a wonderful elloomeerezzhttpwelcomecn'
>>> re.sub(r'[^a-z ]+', '', s)
' m so glad to introduce myself and m years old oday is t is a wonderful elloomeerezzhttpwelcomecn'
>>> re.sub(r'[^A-Za-z ]', '', s)
'I m so glad to introduce myself and Im years old Today is It is a wonderful DAY HHHHelloComeHereAAzzhttpwelcomecn'
>>> re.sub(r'[^A-Za-z ]+', '', s)
'I m so glad to introduce myself and Im years old Today is It is a wonderful DAY HHHHelloComeHereAAzzhttpwelcomecn'如果要使句子语义和结构更完整,则要先将其余字符替换为空格(即repl设置为空格),然后去除多余的空格,如下:
>>> s1 = re.sub(r'[^A-Za-z ]+', ' ', s)
>>> s1
' I m so glad to introduce myself and I m years old Today is It is a wonderful DAY HHHHello ComeHere AA zz http welcome cn'
>>> re.sub(r'[ ]+', ' ', s1)
' I m so glad to introduce myself and I m years old Today is It is a wonderful DAY HHHHello ComeHere AA zz http welcome cn'b.去除以 @ 开头的英文单词
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'@[A-Za-z]+', '', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! ,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"c.去除以 ?结尾的英文单词和数字(注意这是中文问号)
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'[A-Za-z]+?', '', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?——http://welcome.cn"
>>> re.sub(r'[0-9A-Za-z]+?', '', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...——http://welcome.cn"d.去除原始字符串中的URL
>>> s
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——http://welcome.cn"
>>> re.sub(r'http[:.]+\S+', '', s)
"大家好,我是一个程序员小白。I 'm so glad to introduce myself, and I’m 18 years old. Today is 2020/01/01. It is a wonderful DAY! @HHHHello,,,#111ComeHere222...66?AA?zz?——"字符串提取—提取数字
re.findall(r'\d+', str(string))
// '\d'是正则表达式,+表示匹配多个,如果不加,就是单个的数字字符串相似度比较
python自带比较相似度的模块,difflib。比较两个字符串的模块是difflib.SequenceMatcher,使用起来很简单:
import difflib
def string_similar(s1, s2):
return difflib.SequenceMatcher(None, s1, s2).quick_ratio()
print string_similar('爱尔眼科沪滨医院', '沪滨爱尔眼科医院')
print string_similar('安定区妇幼保健站', '定西市安定区妇幼保健站')
print string_similar('广州市医院', '广东省中医院')结果:
1.0
0.842105263158
0.606060606061其中None的位置是一个函数,用来去掉自己不想算在内的元素。比如我想把空格排除在外:
seq = difflib.SequenceMatcher(lambda x:x=" ", a, b)
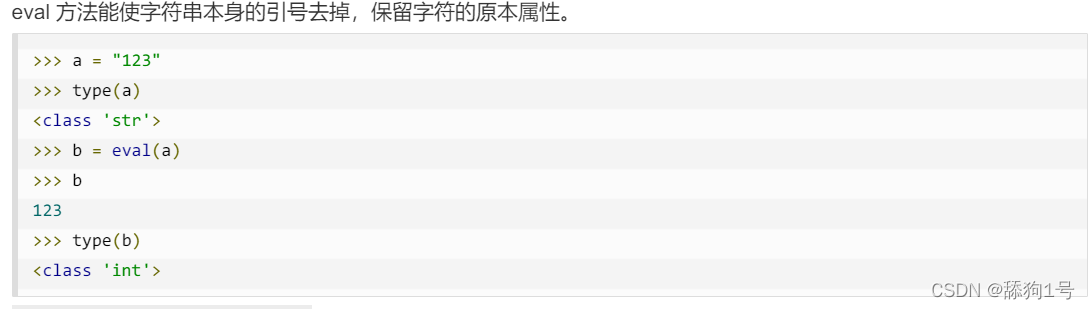
ratio = seq.ratio()去掉字符串两端的引号
背景:有时候会出现这种情况的字符串'"srting"',用type查看,是string。如果里面是整数,需要和某个整数比大小,没法直接用int强制转,需要先去掉外面那层引号
方法:eval()例子:
a='"srting"'
print(a)
b=eval(a)
print(b)
//输出
//"srting"
//srtingeval()用途: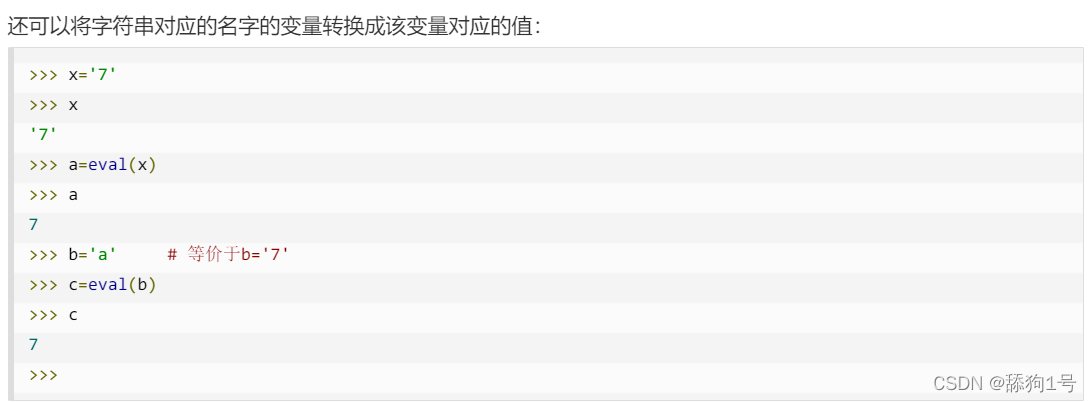
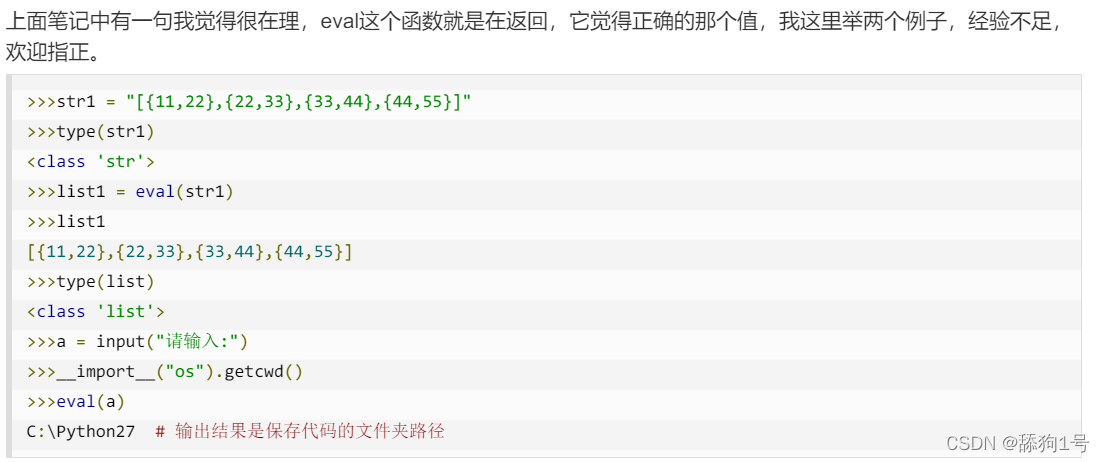

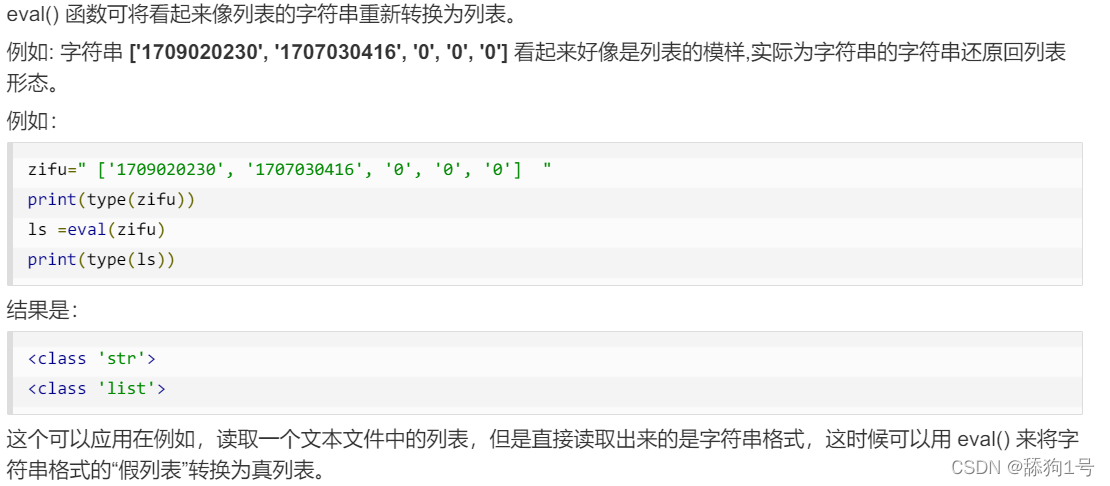
字符串转数字,数字转字符串
字符串str转数字:
float(str)
int(str)
数字num转字符串
str(num)
变量转换
字符串、数字互转看字符串里面的操作
数字、bytes
数字num转bytes:
需将num转为str,再利用codec的encode函数,将str转为bytes:encode(str(num))
bytes转数字:
int(bytes)
float(bytes)
字符串、bytes
字符串转bytes:
from codec import encode,decode
encode(str)
//法二
bytes(str,'UTF-8')bytes转字符串:
//法一
from codec import encode,decode
decode(bytes)
//法二
str(bytes,'UTF-8')循环删除元素
循环删除列表中元素时千万别用正序遍历,一定要用反序遍历!
def test(data):
for i in data:
data.remove(i)
return data
data = [1, 2, 3]
print(test(data))面对以上代码,乍一看以为会打印出空列表,因为test函数内通过for的方法将data中的元素都删除了,其实不然,实际输出如下:
原列表在内存中为:
第一次执行到data.remove(i)时将第一个元素‘1’删除,列表变为:

第二次执行到data.remove(i)时i为第二个元素,即‘3’,此时将‘3’删除,列表变为:

此时列表已经没有第三个元素了,即退出循环,将[2]返回。
如何解决这个问题呢? 我们可以用倒序删除的方法!
def test(data):
for i in data[::-1]:
data.remove(i)
return data
data = [1, 2, 3]
print(test(data))列表相关操作
列表头部插入元素
names.insert(0,'Bill') //第一个参数表示索引两个列表取交集
a=[i for i in list2 if i in list1]或者
list(set(a).intersection(b))列表取并集
list(set(a).union(b))list(set(a) | set(b))多个列表取并集:
list(set(a).intersection(b,c)) 列表取差集
list(set(a).difference(b))list(set(a).difference(b,c)) # 求特定1个list(a)中有,其他list(b、c)都没有的元素"""列表排序(更详细操作见文档)
file_list.sort(key=lambda x:int(x[9:-4]))
//根据关键字来排序,lambda是一个函数的简写。//下面两个写法是一样的
g = lambda x:x+1
def g(x):
return x+1列表替换元素(更详细操作见文档)
1.直接替换
//假设要把列表中的a元素替换为b
//首先得到a的索引,将这个索引的值赋为b
list[list.index(a)]=b2.条件替换
lst = ['1', '2', '3']
rep = ['4' if x == '2' else x for x in lst]
rep
['1', '4', '3']3.批量替换
lst = ['1', '2', '3', '4', '5']
pattern = ['3', '4']
rep = ['d' if x in pattern else x for x in lst]
rep
['1', '2', 'd', 'd', '5']4.映射替换
lst = ['1', '2', '3', '4', '5']
pattern = {'3':'three', '4':'four'}
rep = [pattern[x] if x in pattern else x for x in lst]
rep
['1', '2', 'three', 'four', '5']列表截取元素
l=list[0:4]
注意:列表的正向索引下标是从零开始,不是1,反向索引是到-1结束,不是0
正向索引(01234…)
1.只有头下标i和冒号(代表的是从该头下标i的元素开始截取,一直到最后)
2.只有冒号尾下标i(代表的是从开始一直截取到i-1的元素)
3.头下标i,冒号和尾下标j都有(代表的是从i一直截取到j-1的元素)
例程如下:
list=['123','abc',0,True]
x=list[1:]
y=list[:3]
z=list[2:3]
print(x)
print(y)
print
['abc', 0, True]
['123', 'abc', 0]
[0]反向索引(……-2-1)
1.只有头下标i和冒号(代表的是从该头下标i的元素开始截取,一直到最后)
2.只有冒号尾下标i(代表的是从开始一直截取到i-1的元素)
3.头下标i,冒号和尾下标j都有(代表的是从i一直截取到j-1的元素
例程如下:
list=['123','abc',0,True]
x=list[-3:]
y=list[:-2]
z=list[-3:-1]
print(x)
print(y)
print(z)
['abc', 0, True]
['123', 'abc']
['abc', 0]加入步长的截取:
前面讲到的截取是没有带步长的。如果想隔一定元素个数去截取列表,可以选择使用带有步长的截取方式
格式:
变量[头下标:尾下标:步长]
例如截取第三个到第五个元素,如果隔两个步长截取的话,就会截取到元素3和元素5,元素4就被跳过了
列表查找重复元素
推荐方法二
方法一:
mylist = [1,2,2,2,2,3,3,3,4,4,4,4]
myset = set(mylist)
for item in myset:
print("the %d has found %d" %(item,mylist.count(item)))
the 1 has found 1
the 2 has found 4
the 3 has found 3
the 4 has found 4方法二:
from collections import Counter
a = [1, 2, 3, 4, 3, 2, "奔奔", "benben", "奔奔"]
b = dict(Counter(a))
## 只展示重复元素
print ([key for key,value in b.items() if value > 1])
## 展现重复元素和重复次数
print ({key:value for key,value in b.items()if value > 1})
//结果
[2, 3, '奔奔']
{2: 2, 3: 2, '奔奔': 2}
方法三:
List=[1,2,2,2,2,3,3,3,4,4,4,4]
a = {}
for i in List:
if List.count(i)>1:
a[i] = List.count(i)
print (a)XML相关操作
创建一个XML文档
import xml.dom.minidom
import re,os
list=['a', 'b', 'str_scheme_name', 'str_limiter']
doc = xml.dom.minidom.Document()
root = doc.createElement('version-check')
doc.appendChild(root)
for i in list:
var_name = doc.createElement(i)
version=doc.createElement('version')
version.setAttribute('v','100')
version.appendChild(doc.createTextNode(i))
var_name.appendChild(version)
root.appendChild(var_name)
fp = open('C:/Users/76585/Desktop/shell/cfdname2/tow.xml', 'w')
doc.writexml(fp, indent='\t', addindent='\t', newl='\n', encoding="utf-8")对现有XML文档进行修改
tree=ET.parse('C:/Users/76585/Desktop/shell/cfdname2/tow.xml')
root=tree.getroot()
// b是一个列表
for i in b:
newnode=ET.Element(i)
version=ET.Element('version')
version.attrib={"v":end}
version.text=i
newnode.append(version)
# newnode.text=end
root.append(newnode)
tree.write('C:/Users/76585/Desktop/shell/cfdname2/tow.xml')正则表达式
特殊的去首尾空格方法
strip是trim掉字符串两边的空格。
lstrip, trim掉左边的空格
rstrip, trim掉右边的空格
theString = ' https://mp.csdn.net/postlist '
print theString.strip()判断情况总结
判断目录下的空文件夹并删除
## 导入os
import os
## 让用户自行输入路径
path=input('请输入文件目录路径')
## 获取当前目录下的所有文件夹名称 得到的是一个列表
folders=os.listdir(path)
## # 遍历列表
for folder in folders:
# 将上级路径path与文件夹名称folder拼接出文件夹的路径
folder2=os.listdir(path+'\\'+folder)
print(folder2)
# 若文件夹为空
if folder2==[]:
# 则打印此空文件的名称
print(folder)
# 并将此空文件夹删除
os.rmdir(path+'\\'+folder)判断文件内容为空
方法: size = os.path.getsize(file_path)
- 结果:如果 size == 0,则文件内容为空;
- 上述的 file_path 为需要判断大小的文件的存放路径。
if os.path.getsize(file_path) == 0:
print('文件内容为空')变量类型判断
1、isinstance(参数1,参数2)
描述:该函数用来判断一个变量(参数1)是否是已知的变量类型(参数2) 类似于type()参数1:变量
参数2:可以是直接或间接类名、基本类型或者由它们组成的元组。
返回值: 如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False
方法2
type(num)深拷贝—deep copy
背景:
dict_min['name']=new_line[1]
dict_mid[new_line[1]]=dict_min上面这段代码中,newline[1]发生变化时,dict_min发生变化,从而导致dict_mid受到影响。具体的效果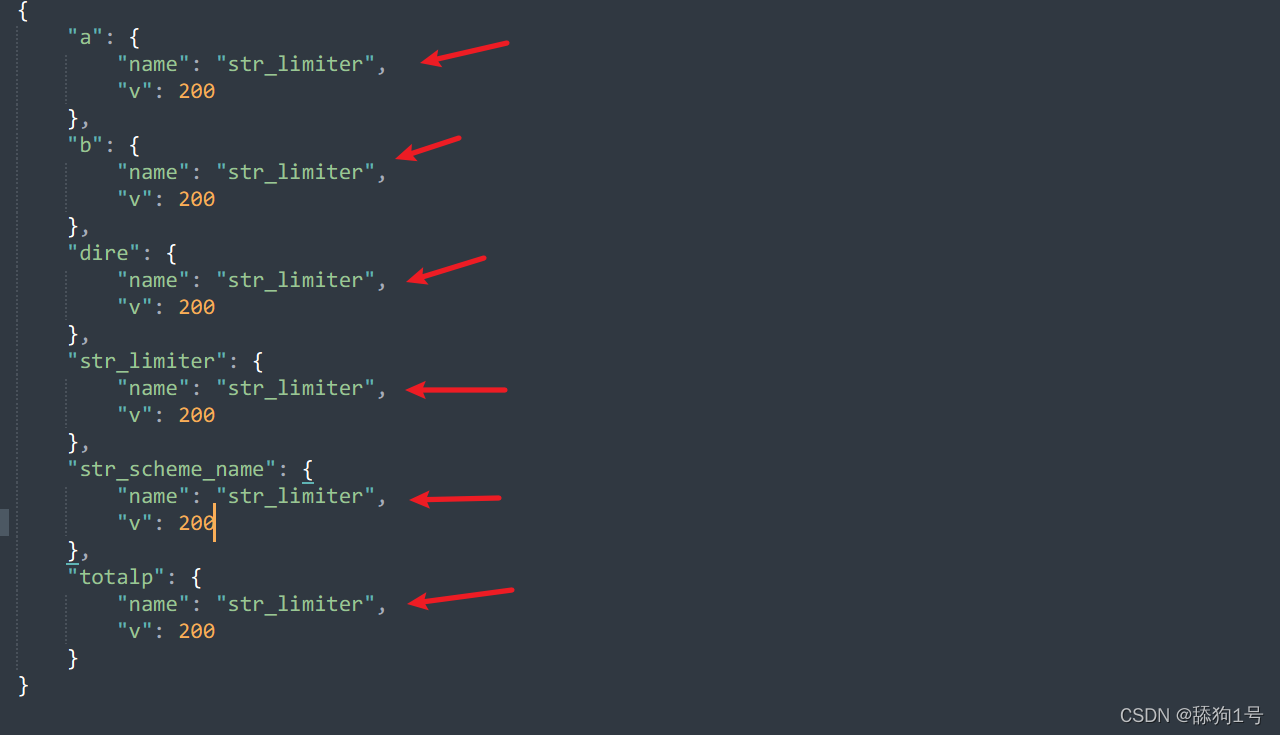
name的值会依次被后面的值覆盖,但我们不希望之前的收到影响。
解决办法:
dict_min['name']=new_line[1]
dict_tmp=copy.deepcopy(dict_min)
dict_mid[new_line[1]]=dict_tmp看下深拷贝的例子:
>>> import copy
>>> origin = [1, 2, [3, 4]]
##origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
##cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
##把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2可以看到 cop1,也就是 shallow copy 跟着 origin 改变了。而 cop2 ,也就是 deep copy 并没有变。
似乎 deep copy 更加符合我们对「复制」的直觉定义: 一旦复制出来了,就应该是独立的了。如果我们想要的是一个字面意义的「copy」,那就直接用 deep_copy 即可。
那么为什么会有 shallow copy 这样的「假」 copy 存在呢? 这就是有意思的地方了。
python的数据存储方式
Python 存储变量的方法跟其他 OOP 语言不同。它与其说是把值赋给变量,不如说是给变量建立了一个到具体值的 reference。
当在 Python 中 a = something 应该理解为给 something 贴上了一个标签 a。当再赋值给 a 的时候,就好象把 a 这个标签从原来的 something 上拿下来,贴到其他对象上,建立新的 reference。 这就解释了一些 Python 中可能遇到的诡异情况:
>> a = [1, 2, 3]
>>> b = a
>>> a = [4, 5, 6] //赋新的值给 a
>>> a
[4, 5, 6]
>>> b
[1, 2, 3]
## a 的值改变后,b 并没有随着 a 变
>>> a = [1, 2, 3]
>>> b = a
>>> a[0], a[1], a[2] = 4, 5, 6 //改变原来 list 中的元素
>>> a
[4, 5, 6]
>>> b
[4, 5, 6]
## a 的值改变后,b 随着 a 变了上面两段代码中,a 的值都发生了变化。区别在于,第一段代码中是直接赋给了 a 新的值(从 [1, 2, 3] 变为 [4, 5, 6]);而第二段则是把 list 中每个元素分别改变。
而对 b 的影响则是不同的,一个没有让 b 的值发生改变,另一个变了。怎么用上边的道理来解释这个诡异的不同呢?
首次把 [1, 2, 3] 看成一个物品。a = [1, 2, 3] 就相当于给这个物品上贴上 a 这个标签。而 b = a 就是给这个物品又贴上了一个 b 的标签。
第一种情况:
a = [4, 5, 6] 就相当于把 a 标签从 [1 ,2, 3] 上撕下来,贴到了 [4, 5, 6] 上。
在这个过程中,[1, 2, 3] 这个物品并没有消失。 b 自始至终都好好的贴在 [1, 2, 3] 上,既然这个 reference 也没有改变过。 b 的值自然不变。
第二种情况:
a[0], a[1], a[2] = 4, 5, 6 则是直接改变了 [1, 2, 3] 这个物品本身。把它内部的每一部分都重新改装了一下。内部改装完毕后,[1, 2, 3] 本身变成了 [4, 5, 6]。
而在此过程当中,a 和 b 都没有动,他们还贴在那个物品上。因此自然 a b 的值都变成了 [4, 5, 6]。
搞明白这个之后就要问了,对于一个复杂对象的浅copy,在copy的时候到底发生了什么?
再看一段代码:
>>> import copy
>>> origin = [1, 2, [3, 4]]
##origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
##cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
##把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2学过docker的人应该对镜像这个概念不陌生,我们可以把镜像的概念套用在copy上面。
copy对于一个复杂对象的子对象并不会完全复制,什么是复杂对象的子对象呢?就比如序列里的嵌套序列,字典里的嵌套序列等都是复杂对象的子对象。对于子对象,python会把它当作一个公共镜像存储起来,所有对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变了之后另一个引用使用镜像的时候镜像已经被改变了。
所以说看这里的origin[2],也就是 [3, 4] 这个 list。根据 shallow copy 的定义,在 cop1[2] 指向的是同一个 list [3, 4]。那么,如果这里我们改变了这个 list,就会导致 origin 和 cop1 同时改变。这就是为什么上边 origin[2][0] = “hey!” 之后,cop1 也随之变成了 [1, 2, [‘hey!’, 4]]。
deepcopy的时候会将复杂对象的每一层复制一个单独的个体出来。
这时候的 origin[2] 和 cop2[2] 虽然值都等于 [3, 4],但已经不是同一个 list了。即我们寻常意义上的复制。
json相关操作
dumps和dump 序列化方法
dumps只完成了序列化为str,
dump必须传文件描述符,将序列化的str保存到文件中
下面使用实际的例子依次介绍:
import json
key={ "people": [
{ "Name": "Brett", "名字":"McLaughlin", '1': 1 },
{ "Name": "Jason", "名字":"Hunter", '2': 1},
{ "Name": "Elliotte", "名字":"Harold", '3': 1 }
]}
print(json.dumps(key,sort_keys=True,indent =4,ensure_ascii=False))输出效果如下:
{
"people": [
{
"1": 1,
"Name": "Brett",
"名字": "McLaughlin"
},
{
"2": 1,
"Name": "Jason",
"名字": "Hunter"
},
{
"3": 1,
"Name": "Elliotte",
"名字": "Harold"
}
]
}非常简便的将所需要的数据流畅的保存下来了,下面我们介绍相关的参数:
(1)indent=4:缩进,python中默认缩进是4个,前端和css默认是2个
(2)sort_keys=True/False:以key为标准,按key的a-z字母排序
(3)separators=(‘,’,‘:’):减少空格,增加传输速度,参数是要保留的标点符号,json只保留 逗号和冒号就行。
下面我们将其保存在json的文件中:
with open("E:\\测试.json", "w+",encoding='utf-8_sig')as f:
json.dump(key,f,sort_keys=True,indent =4,ensure_ascii=False)
//另外一种写法
f= open("E:\\测试.json", "w",encoding='utf-8_sig') //可能会报encoding的相关错,去掉就好loads和load 反序列化方法
loads 只完成了反序列化,
load 只接收文件描述符,完成了读取文件和反序列化
同样用上述例子介绍:
key_1=json.dumps(key,sort_keys=True,indent =4,ensure_ascii=False)
print(json.loads(key_1))输出为:
{'people': [{'1': 1, 'Name': 'Brett', '名字': 'McLaughlin'}, {'2': 1, 'Name': 'Jason', '名字': 'Hunter'}, {'3': 1, 'Name': 'Elliotte', '名字': 'Harold'}]}即将其反输出
下面读取json文件也是一样的:
with open("E:\\测试.json", "r+",encoding='utf-8_sig')as f:
data=json.load(f)
print(data)特别注意:
如果打开的文件为空,那么json.load(f)会报错,里面必须有内容才能用这个打开
字典相关操作
如何检查字典(Python)中是否存在某个值
d = {‘1’: ‘one’, ‘3’: ‘three’, ‘2’: ‘two’, ‘5’: ‘five’, ‘4’: ‘four’}
我需要一种方法来找出这个字典中是否存在诸如“one”或“two”这样的值。
>>> d = {'1': 'one', '3': 'three', '2': 'two', '5': 'five', '4': 'four'}
>>> 'one' in d.values()
True强制结束程序或暂停程序
import sys
sys.exit()##暂停程序
input()
用法:直接在欲等待处输入input()即可。
特点:
优点:不需要借助模块,执行到此处阻塞等待人工输入。
缺点:程序结束时候需要强制结束或者在控制台输入值。
time.sleep()
用法:导入time模块;在欲等待处输入time.sleep(time)(time为数字,表示秒)即可。
特点:
优点:动态等待程序执行完毕,不需要强行终止,等待时间可调。
缺点:需要导入模块,等待规定时间结束后便继续往下执行。
os.system("pause")
用法:导入os模块;在欲等待处输入os.system("pause")即可。
特点:
优点:不必强行终止;不必等待时间,可自由按下enter继续。
缺点:导入模块,执行系统命令。python执行shell脚本
os.system(“command”)
这是python自带的执行shell命令的方法,其中最后一个0是这个命令的返回值,为0表示命令执行成功。但是使用system()无法将执行的结果保存起来。
import os
print(os.system("touch a.txt")) //需要用引号将命令括起来
os.popen(“command”)方法
上面的os.system()方法没办法查看shell命令返回的结果,通过 os.popen() 返回的是 file read 的对象,对其进行读取 read() 的操作可以看到执行的输出。
注意:os.popen() 返回的是一个文件对象f哦!!!
import os
f=os.popen("ls -l") # 返回的是一个文件对象
print(f.read()) # 通过文件的read()读取所返回的内容
'''
total 4
-rw-rw-r-- 1 tengjian tengjian 0 11月 5 09:32 a.txt
-rw-rw-r-- 1 tengjian tengjian 81 11月 5 09:32 python_shell.py
'''
对于有返回值的shell命令,建议使用 os.popen()
对于没有返回值的shell命令,建议使用 os.system()
在for循环体内修改i值
场景:在循环体内判断条件发生时,重新执行执行当前循环体(保留当前i值)
常规:类似的需求一般会在循环体里写一个 if 加上continue / break
实际:但是在for循环内修改i值,只会对当前一次的循环体内有效
for i in range(1,5):
print("i in use:", i)
i = 20
print("i modified:", i)//结果
i in use: 1
i modified: 20
i in use: 2
i modified: 20
i in use: 3
i modified: 20
i in use: 4
i modified: 20原理:想想 in 操作符的概念,应该就能明白了
解读:每次for循环,相当于是从range(1,5)这个类似list里做取数的动作,修改的只是取出的值,并不是取数来源的值
解决:使用 while 替换 for
i = 1
while i < 6:
print(i)
if(i % 2 == 0):
i += 2
i += 1//结果
1
2
5修改文件
##!/usr/bin/env python
## -*- coding: utf-8 -*-
## @Date : 2019-04-25 14:35:58
## @Author : 迷风小白
def changetext(a,b):
with open('test','r',encoding='utf-8') as f:
lines=[] # 创建了一个空列表,里面没有元素
for line in f.readlines():
if line!='\n':
lines.append(line)
f.close()
with open('test','w',encoding='utf-8') as f:
for line in lines:
if a in line:
line = b
f.write('%s\n' %line) //关键代码
else:
f.write('%s' %line) //关键代码
changetext('pig','cow')windows切换python2和python3
同时装了Python3和Python2,怎么用pip? - 知乎
已经安装了python2和python3,且Python3(>=3.3);运行python2 使用py -2 hello.py;运行python3 使用py -3 hello.py
去掉参数 -2/-3
每次运行都要加入参数-2/-3还是比较麻烦,所以py.exe这个启动器允许你在代码中加入说明,表明这个文件应该是由python2解释运行,还是由python3解释运行。说明的方法是在代码文件的最开始加入一行
#! python2或者
#! python3分别表示该代码文件使用Python2或者Python3解释运行。这样,运行的时候你的命令就可以简化为
py hello.py如何使用pip
py -2 -m pip install XXXX-2 还是表示使用 Python2,-m pip 表示运行 pip 模块,也就是运行pip命令了。如果是为Python3安装软件,那么命令类似的变成
py -3 -m pip install XXXX知识点
from import和import的区别
import Module # 引入模块
from Module import Other # 引入模块中的类、函数或者变量
from Module import * # 引入模块中的所有‘公开’成员举例
from datetime import datetime
##引入 datetime 模块中的 datetime 类,然后就可以通过datetime这个类调用now() 方法了
##即,内部可以通过datetime.now()来调用import datetime
##引入datetime 模块,然后通过这个模块来调用模块中的类datetime和类datetime中的方法now()
##即:内部可以通过datetime.datetime.now()来调用
也就是说,有一个模块datetime,这个模块中有一个类datetime,在这个类中有一个方法now()


