查看环境变量
go version //查看版本
go env //查看环境变量安装golang、gopath、goroot
安装
windows安装一路点击ok就好。
Linux安装:
- wget https://dl.google.com/go/go1.14.1.linux-amd64.tar.gz
- tar -zxvf go1.14.1.linux-amd64.tar.gz -C /usr/local # 解压
配置环境变量: Linux下有两个文件可以配置环境变量,其中/etc/profile是对所有用户生效的;$HOME/.profile是对当前用户生效的,根据自己的情况自行选择一个文件打开,添加如下两行代码,保存退出。
export GOROOT=/usr/local/go export PATH=$PATH:$GOROOT/bin修改/etc/profile后要重启生效,修改$HOME/.profile后使用source命令加载$HOME/.profile文件即可生效。 检查:
go versiongopath、goroot
goroot:
其实就是golang 的安装路径
当你安装好golang之后其实这个就已经有了gopath:
作用:
存放sdk以外的第三方类库
自己收藏的可复用的代码
目录结构:$GOPATH目录约定有三个子目录
src存放源代码(比如:.go .c .h .s等) 按照golang默认约定,go run,go install等命令的当前工作路径(即在此路径下执行上述命令)。
pkg编译时生成的中间文件(比如:.a) golang编译包时
bin编译后生成的可执行文件(为了方便,可以把此目录加入到 P A T H 变 量 中 , 如 果 有 多 个 g o p a t h , 那 么 使 用 PATH 变量中,如果有多个gopath,那么使用PATH变量中,如果有多个gopath,那么使用{GOPATH/bin:}/bin添加所有的bin目录)
package
包的定义
package 包名注意事项:
- 一个文件夹下直接包含的文件只能归属于一个package,同样一个package的文件不能在多个文件夹下。
- 包名可以不和文件夹的名字一样。
- 包名为
main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不含main包的源代码则不会得到可执行文件
包的使用
- 有时候我们单独写一个go文件,测试或验证某个功能,包名都写main就好
- 如果要引入自定义的包。如果import失败,看一下保存的信息。一般会提示GOROOT GOPATH找不到这个包,这个时候把这个文件夹放到上面的目录里面就可以导入了。
举例:
我目前的GOROOT是在这个目录下面,把文件夹放进去,里面是go文件,就可以引入了。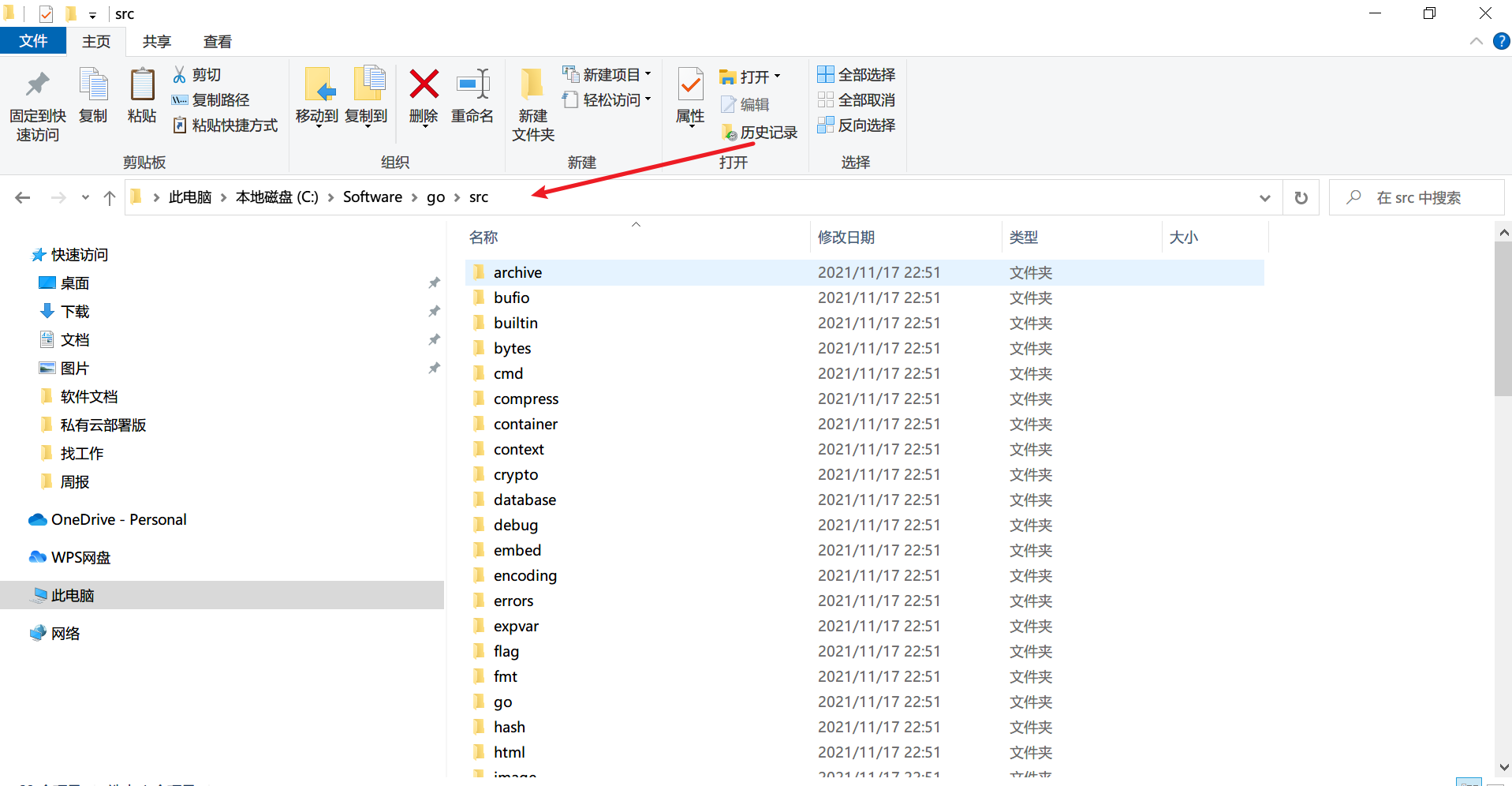
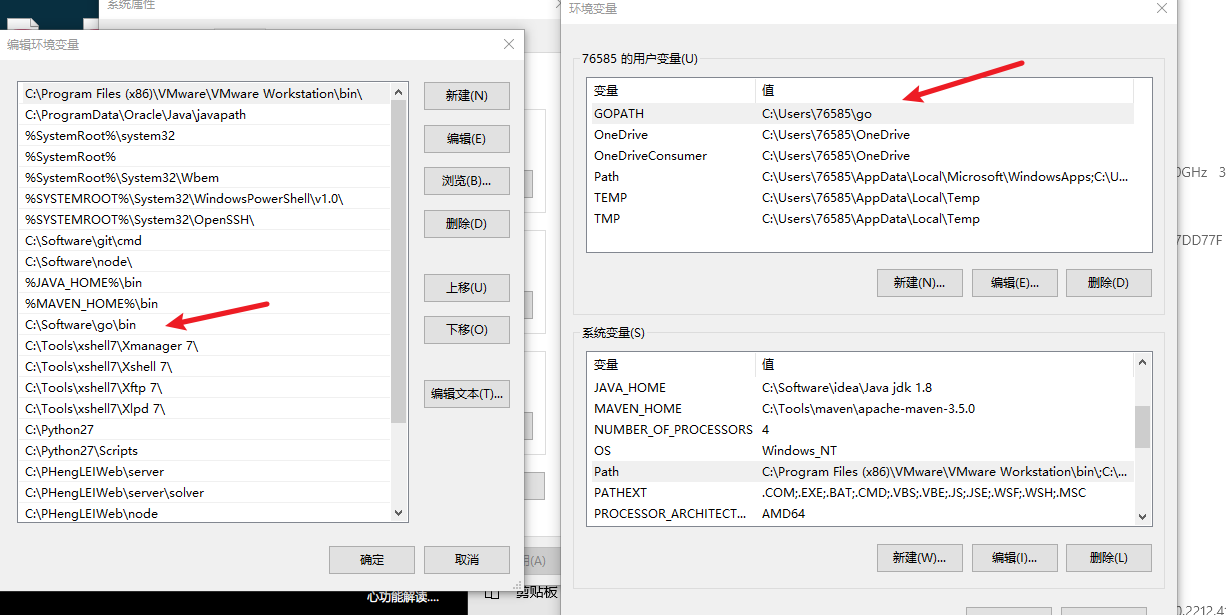
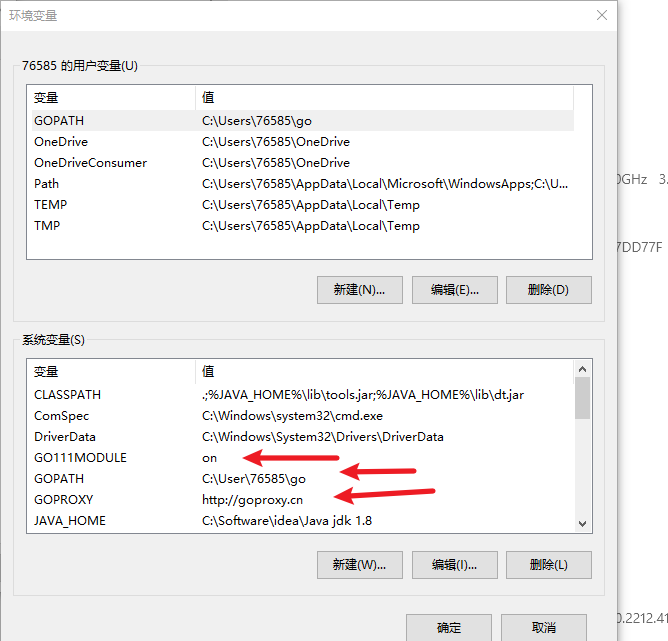
go mod配置
go mod 主要用于管理第三方包,可以自动进行下载。要使用go mod,需要一些配置。
需要配置GO111MODULE 、GOPROXY
go mod使用
首先:
go mod init "modname"
//modname一般是文件所处文件夹的名字
//go mod init dynamic如果要某文件要引入一些包,在import处写入,然后执行下面命令:
go mod tidy
//或者
go get -u导入第三方包
背景:和公司合作开发,但是没有他们内部的开发环境,只能让他们把包单独抽出来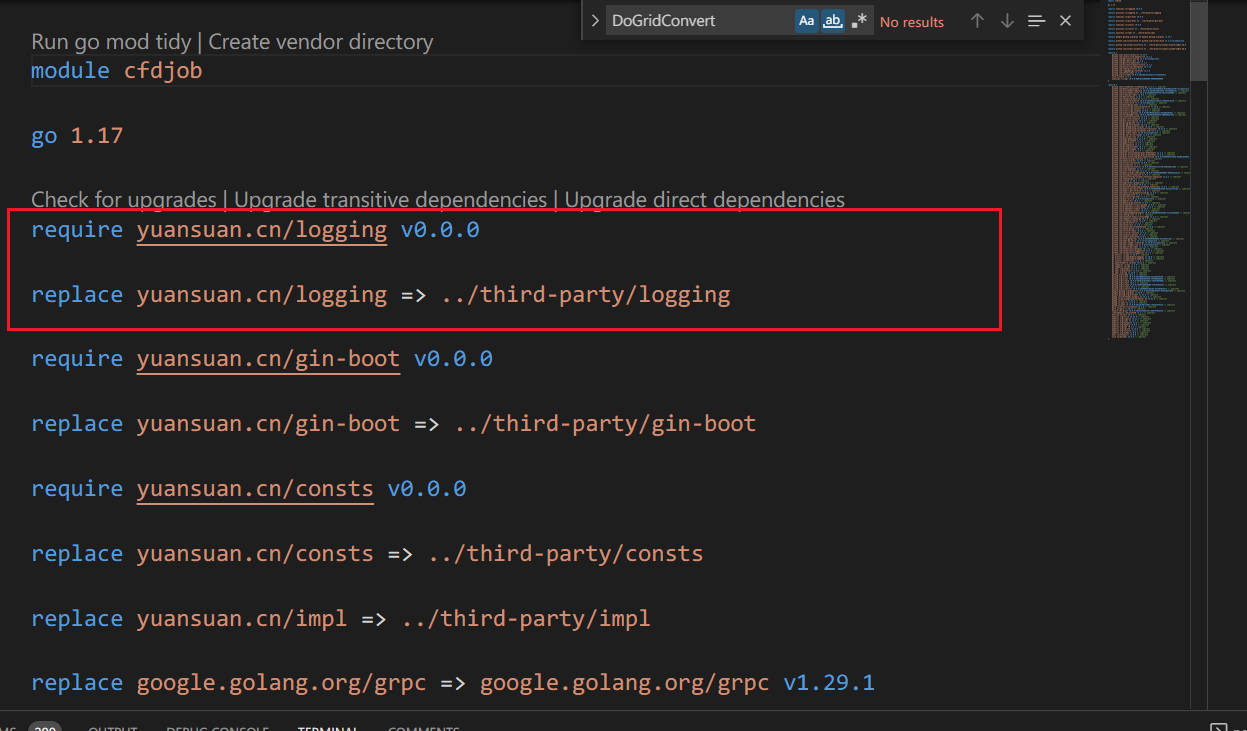
核心就是这里的replace,不用修改goproxy或者go111module等环境变量
语法
Context
Context主要做两件事情:
- 通知子协程提前退出
- 携带环境变量
channel
Goroutine(协程) 使用 Channel 传递数据
定义
// 只读 channel
var readOnlyChan <-chan int // channel 的类型为 int
// 只写 channel
var writeOnlyChan chan<- int
// 可读可写
var ch chan int
// 或者使用 make 直接初始化
readOnlyChan1 := make(<-chan int, 2) // 只读且带缓存区的 channel
readOnlyChan2 := make(<-chan int) // 只读且不带缓存区 channel
writeOnlyChan3 := make(chan<- int, 4) // 只写且带缓存区 channel
writeOnlyChan4 := make(chan<- int) // 只写且不带缓存区 channel
ch := make(chan int, 10) // 可读可写且带缓存区
ch <- 20 // 写数据
i := <-ch // 读数据
i, ok := <-ch // 还可以判断读取的数据操作channel
操作 channel 一般有如下三种方式:
读 <-ch
写 ch<-
关闭 close(ch)
go func(){}()
go func() {
.....
}()以并发的方式调用匿名函数func
详细解释:
func(name string) {
fmt.Println("Your name is", name)
} (str) //这里的(str)是?其实,这就是在调用这个函数,这种写法等同于:
f := func(name string) {
fmt.Println("Your name is", name)
}
f(str) //看吧,就是把函数复制给变量,变量(函数)传参
以下两段代码执行结果等同:
代码一:
package main
import (
"fmt"
)
func main() {
str := "xulinlin"
func(name string) {
fmt.Println("Your name is", name)
}(str)
}
代码二:
package main
import (
"fmt"
)
func main() {
f := func(name string) {
fmt.Println("Your name is", name)
}
f(str)
}
输出都是:
Your name is xulinlindefer
defer后面的函数在defer语句所在的函数执行结束的时候会被调用,用来做一些收尾工作
原文链接)
Println 与 Printf 的区别
- Println :可以打印出字符串,和变量
- Printf : 只可以打印出格式化的字符串,可以输出字符串类型的变量,不可以输出整形变量和整形
也就是说,当需要格式化输出信息时一般选择 Printf,其他时候用 Println 就可以了,比如:
a := 10
fmt.Println(a) //right
fmt.Println("abc") //right
fmt.Printf("%d",a) //right
fmt.Printf(a) //errorprintf格式化输出
通用输出
%v #仅输出该变量的值 %+v #输出 该变量的值,如果是数组k/v 则将k/v都输出 %#v #先输出结构体名字值,再输出结构体(字段名字+字段的值) %T #输出结构体名称 %% #百分号package main import ( "fmt" ) type student struct { id int name string } func main() { ss := student{id: 1,name: "test"} fmt.Printf("%v \n",ss) //%v 当碰到数组时,仅输出value,不输出key fmt.Printf("%+v \n",ss) //%+v 当碰到数组时,将key-value 都输出 fmt.Printf("%#v \n",ss) //%#v 输出时,会将方法名 +k/v都输出 fmt.Printf("%T \n",ss) //%T 输出结构体名称() fmt.Printf("%% \n") //%% 没有意义,只是输出一个% }整数类型
%b 二进制表示 %c 相应Unicode码点所表示的字符 %d 十进制表示 %o 八进制表示 %q 单引号围绕的字符字面值,由Go语法安全地转义 %x 十六进制表示,字母形式为小写 a-f %X 十六进制表示,字母形式为大写 A-F %U Unicode格式:123,等同于 "U+007B"
package main
import (
"fmt"
)
func main() {
ss := 68
fmt.Printf("%b \n",ss) //二进制表示
fmt.Printf("%c \n",ss) //Unicode码表示的字符
fmt.Printf("%d \n",ss) //十进制表示
fmt.Printf("%o \n",ss) //八进制
fmt.Printf("%q \n",ss) //输出字符,单引号包裹
fmt.Printf("%x \n",ss) //十六进制输出 小写
fmt.Printf("%X \n",ss) //十六进制输出 大写
fmt.Printf("%U \n",ss) //Unicode格式
}- 浮点数
%b 无小数部分、二进制指数的科学计数法,如-123456p-78;参见strconv.FormatFloat %e 科学计数法,如-1234.456e+78 %E 科学计数法,如-1234.456E+78 %f 有小数部分但无指数部分,如123.456 %F 等价于%f %g 根据实际情况采用%e或%f格式(以获得更简洁、准确的输出) %G 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出)
package main
import (
"fmt"
)
func main() {
fmt.Printf("%b \n",68.10) //二进制输出
fmt.Printf("%e \n",68.10) //科学计数法 e
fmt.Printf("%E \n",68.10) //科学计数法 E
fmt.Printf("%f \n",68.10)
fmt.Printf("%g \n",68.10)
fmt.Printf("%G \n",68.10)
}//结果
4792111478498918p-46
6.810000e+01
6.810000E+01
68.100000
68.1
68.1
- 布尔
%t true 或 false - 字符串
%s 字符串或切片的无解译字节 %q 双引号围绕的字符串,由Go语法安全地转义 %x 十六进制,小写字母,每字节两个字符 %X 十六进制,大写字母,每字节两个字符package main import ( "fmt" ) func main() { fmt.Printf("%s","I'm a girl") fmt.Println() fmt.Printf("%q","I'm a girl") fmt.Println() fmt.Printf("%x","I'm a girl") fmt.Println() fmt.Printf("%X","I'm a girl") fmt.Println() }
//结果
I'm a girl
"I'm a girl"
49276d2061206769726c
49276D2061206769726C占位符
原文链接
输出为:
{Aric 21 3-1}
{Name:Aric Age:21 Class:3-1}
main.Student{Name:"Aric", Age:21, Class:"3-1"}
main.Student
676f6c616e67
676F6C616E67
0xc000062150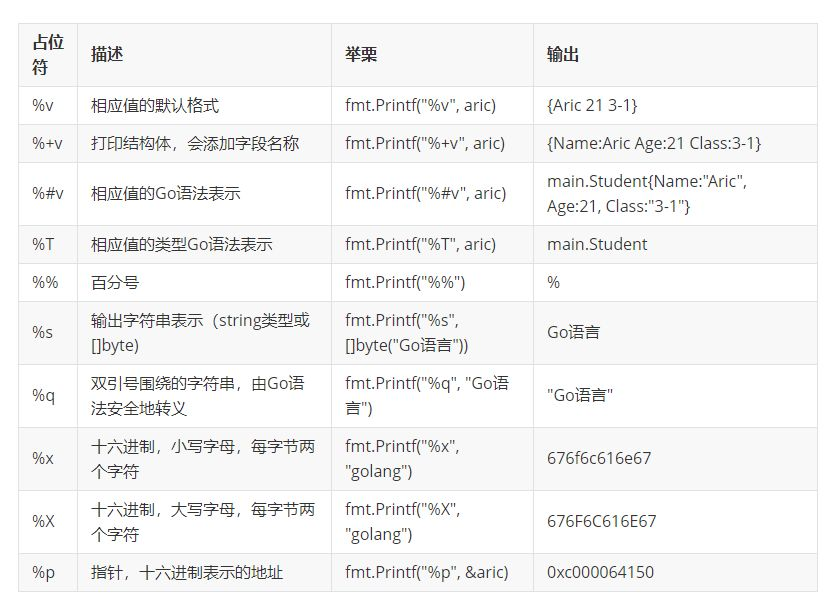
下划线 “_”
“_”是特殊标识符,用来忽略结果。
1.下划线在import中
在Golang里,import的作用是导入其他package。
import 下划线(如:import _ hello/imp)的作用:当导入一个包时,该包下的文件里所有init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。这个时候就可以使用 import _ 引用该包。即使用【import _ 包路径】只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
示例:
src
|
+--- main.go
|
+--- hello
|
+--- hello.gomain.go
package main
import _ "./hello"
func main() {
// hello.Print()
//编译报错:./main.go:6:5: undefined: hello
}hello.go
package hello
import "fmt"
func init() {
fmt.Println("imp-init() come here.")
}
func Print() {
fmt.Println("Hello!")
}输出结果:
imp-init() come here.2.下划线在代码中
package main
import (
"os"
)
func main() {
buf := make([]byte, 1024)
f, _ := os.Open("/Users/***/Desktop/text.txt")
defer f.Close()
for {
n, _ := f.Read(buf)
if n == 0 {
break
}
os.Stdout.Write(buf[:n])
}
}解释1:
下划线意思是忽略这个变量.
比如os.Open,返回值为*os.File,error
普通写法是f,err := os.Open("xxxxxxx")
如果此时不需要知道返回的错误值
就可以用f, _ := os.Open("xxxxxx")
如此则忽略了error变量解释2:
占位符,意思是那个位置本应赋给某个值,但是咱们不需要这个值。
所以就把该值赋给下划线,意思是丢掉不要。
这样编译器可以更好的优化,任何类型的单个值都可以丢给下划线。
这种情况是占位用的,方法返回两个结果,而你只想要一个结果。
那另一个就用 "_" 占位,而如果用变量的话,不使用,编译器是会报错的。补充:
import "database/sql"
import _ "github.com/go-sql-driver/mysql"第二个import就是不直接使用mysql包,只是执行一下这个包的init函数,把mysql的驱动注册到sql包里,然后程序里就可以使用sql包来访问mysql数据库了。
= 和 :=的区别
// = 使用必须使用先var声明例如:
var a
a=100
//或
var b = 100
//或
var c int = 100
// := 是声明并赋值,并且系统自动推断类型,不需要var关键字
d := 100String()方法
对于定于了String()方法的类型,默认输出的时候会调用该方法,实现字符串的打印。例如下面代码:
package main
import "fmt"
type Man struct {
name string
}
func (m Man) String() string {
return "My name is :" + m.name
}
func main() {
var m Man
m.name = "SNS"
fmt.Println(m)
}
输出:
My name is :SNS使用指针
然而,如果使用func (m *Man) String() string方式定义函数,那么就不会自动调用该函数输出(go version go1.12.1 windows/amd64)。
package main
import "fmt"
type Man struct {
name string
}
func (m *Man) String() string {
return "My name is :" + m.name
}
func main() {
var m Man
m.name = "SNS"
fmt.Println(m)
}
输出:
{SNS}String方法是接口方法,存在于fmt包里print.go文件下的Stringer接口。go使用fmt包的输出方法会自动调用String()方法。当重写的String是指针方法时,只有指针类型调用的时候才会正常调用,值类型调用的时候实际上没有执行重写的String方法;当重写的String方法是值方法时,无论指针类型和值类型均可调用重写的String方法。其实跟接口的实现有关,当值类型实现接口的时候,相当于值类型和该值的指针类型均实现了该接口;相反,当指针类型实现了该接口的时候,只有指针类型实现了接口,值类型是没有实现的。
最后一句改成
fmt.Println(&m)
因为你只为*Man这个Man的指针类型重新定义了String()方法,所以只有在输出*Man类型的数据时才会调用自定义的String()方法。
而你定义的m是Man类型的,所以才不会调用你定义的String方法。
所要么向楼上那位一样定义Man类型。要么就是在输出时,向Print函数传递Man类型的数据(改成fmt.Println(&m))
方法接受者
原文链接
在go语言中,没有类的概念但是可以给类型(结构体,自定义类型)定义方法。所谓方法就是定义了接受者的函数。接受者定义在func关键字和函数名之间:
type Person struct {
name string
age int
}
func (p Person) say() {
fmt.Printf("I'm %s,%d years old\n",p.name,p.age)
}有了对方法及接受者的简单认识之后,接下来主要谈一下接受者的类型问题。
接受者类型可以是struct,也可以是指向struc的指针。
情况一:接受者是struct
package main
import "fmt"
type Person struct {
name string
age int
}
func (p Person) say() {
fmt.Printf("I'm %s,%d years old\n",p.name,p.age)
}
func (p Person) older(){
p.age = p.age +1
}
func main() {
var p1 Person = Person{"zhansan",16}
p1.older()
p1.say()
//output: I'm zhangsan,16 years old
var p2 *Person = &Person{"lisi",17}
p2.older()
p2.say()
//output: I'm lisi,17 years old
}对于p1的调用,读者应该不会有什么疑问。
对于p2的调用可能存在这样的疑问,p2明明是个指针,为什么再调用了older方法之后,打印结果还是17 years old?
方法的接受者是Person而调用者是Person ,其实在p2调用时存在一个转换p2.older() -> p2.older(); p2.say() -> p2.say()
p2是什么想必读者也是明白的(就一个p2指向Person实例)。那么疑问也就自然的解开了,方法执行时的接受者实际上还是一个值而非引用。
情况二:接受者是指针
package main
import "fmt"
type Person struct {
name string
age int
}
func (p *Person) say() {
fmt.Printf("I'm %s,%d years old\n",p.name,p.age)
}
func (p *Person) older(){
p.age = p.age +1
}
func main() {
var p1 Person = Person{"zhansan",16}
p1.older()
p1.say()
//output: I'm zhangsan,17 years old
var p2 *Person = &Person{"lisi",17}
p2.older()
p2.say()
//output: I'm lisi,18 years old
}p1的调用中也存在一个转换,
p1.older -> p1.older
p1.say() -> p1.say()
用例:
package main
import (
"fmt"
)
//面向对象
//go仅支持封装,不支持继承和多态
//go语言中没有class,只要struct
//不论地址还是结构本身,一律使用.来访问成员
//要改变内容必须使用指针接收者
//结构过大考虑指针接收者
//值接收者是go语言特有
//封装
//名字一般使用CamelCase
//首字母大写: public
//首字母小写:private
//包
//每个目录一个包,包名可以与目录不一样
//main包包含可执行入口,只有一个main包
//为结构定义的方法必须放在同一个包内,但是可以是不同文件
type treeNode struct {
value int
left, right *treeNode
}
func (node treeNode) print() { //显示定义和命名方法接收者(括号里)
fmt.Print(node.value) //只有使用指针才可以改变结构内容
fmt.Println()
}
func (node *treeNode) setValue ( value int) { //使用指针作为方法接收者
if node == nil {
fmt.Println("setting value to nil node") //nil指针也可以调用方法
return
}
node.value = value
}
func (node *treeNode ) traverse(){
if node == nil{
return
}
node.left.traverse()
node.print()
node.right.traverse()
}
func main() {
var root treeNode
fmt.Println(root) //{0 <nil> <nil>}
root = treeNode{value:3}
root.left = &treeNode{}
root.right = &treeNode{5,nil,nil}
root.right.left = new(treeNode)
nodes := []treeNode {
{value: 3},
{},
{6,nil,&root},
}
fmt.Println(nodes) //[{3 <nil> <nil>} {0 <nil> <nil>} {6 <nil> 0xc04205a3e0}]
root.print() // 3
fmt.Println()
root.right.left.setValue(100)
root.right.left.print() //100
fmt.Println()
var pRoot *treeNode
pRoot.setValue(200) //setting value to nil node
pRoot = &root
pRoot.setValue(300)
pRoot.print() //300
root.traverse() //300 0 300 100 5
}结构体定义中的 json 单引号(``)
package main
import (
"encoding/json"
"fmt"
)
//在处理json格式字符串的时候,经常会看到声明struct结构的时候,属性的右侧还有小米点括起来的内容。`TAB键左上角的按键,~线同一个键盘`
type Student struct {
StudentId string `json:"sid"`
StudentName string `json:"sname"`
StudentClass string `json:"class"`
StudentTeacher string `json:"teacher"`
}
type StudentNoJson struct {
StudentId string
StudentName string
StudentClass string
StudentTeacher string
}
//可以选择的控制字段有三种:
// -:不要解析这个字段
// omitempty:当字段为空(默认值)时,不要解析这个字段。比如 false、0、nil、长度为 0 的 array,map,slice,string
// FieldName:当解析 json 的时候,使用这个名字
type StudentWithOption struct {
StudentId string //默认使用原定义中的值
StudentName string `json:"sname"` // 解析(encode/decode) 的时候,使用 `sname`,而不是 `Field`
StudentClass string `json:"class,omitempty"` // 解析的时候使用 `class`,如果struct 中这个值为空,就忽略它
StudentTeacher string `json:"-"` // 解析的时候忽略该字段。默认情况下会解析这个字段,因为它是大写字母开头的
}
func main() {
//NO.1 with json struct tag
s := &Student{StudentId: "1", StudentName: "fengxm", StudentClass: "0903", StudentTeacher: "feng"}
jsonString, _ := json.Marshal(s)
fmt.Println(string(jsonString))
//{"sid":"1","sname":"fengxm","class":"0903","teacher":"feng"}
newStudent := new(Student)
json.Unmarshal(jsonString, newStudent)
fmt.Println(newStudent)
//&{1 fengxm 0903 feng}
//Unmarshal 是怎么找到结构体中对应的值呢?比如给定一个 JSON key Filed,它是这样查找的:
// 首先查找 tag 名字(关于 JSON tag 的解释参看下一节)为 Field 的字段
// 然后查找名字为 Field 的字段
// 最后再找名字为 FiElD 等大小写不敏感的匹配字段。
// 如果都没有找到,就直接忽略这个 key,也不会报错。这对于要从众多数据中只选择部分来使用非常方便。
//NO.2 without json struct tag
so := &StudentNoJson{StudentId: "1", StudentName: "fengxm", StudentClass: "0903", StudentTeacher: "feng"}
jsonStringO, _ := json.Marshal(so)
fmt.Println(string(jsonStringO))
//{"StudentId":"1","StudentName":"fengxm","StudentClass":"0903","StudentTeacher":"feng"}
//NO.3 StudentWithOption
studentWO := new(StudentWithOption)
js, _ := json.Marshal(studentWO)
fmt.Println(string(js))
//{"StudentId":"","sname":""}
studentWO2 := &StudentWithOption{StudentId: "1", StudentName: "fengxm", StudentClass: "0903", StudentTeacher: "feng"}
js2, _ := json.Marshal(studentWO2)
fmt.Println(string(js2))
//{"StudentId":"1","sname":"fengxm","class":"0903"}
}基本数据类型操作
数组
map相关操作
创建map
//初始化空map
prevNums := map[int]int{}
//初始化
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
//value接收任意数据类型,用interface
resMap := make(map[string]interface{})查看元素在集合中是否存在
capital, ok := countryCapitalMap [ "American" ] /*如果确定是真实的,则存在,否则不存在 */
/*fmt.Println(capital) */
/*fmt.Println(ok) */
if (ok) {
fmt.Println("American 的首都是", capital)
} else {
fmt.Println("American 的首都不存在")
}判断key是否存在
package main
import "fmt"
func main() {
demo := map[string]bool{
"a": false,
}
//错误,a存在,但是返回false
fmt.Println(demo["a"])
//正确判断方法
_, ok := demo["a"]
fmt.Println(ok)
}if _, ok := map[key]; ok {
// 存在
}
if _, ok := map[key]; !ok {
// 不存在
}快速删除所有元素
直接重新生成map,名字相同
Map 实现去重与 set 的功能
package main
var set = map[string]bool {
}
func main() {
...
url := xxx
if set[url] {
// 表示集合中已经存在
return
}
set[url] = true // 否则如果不存在,设置为true
}
// 完成后,set的所有的key值为不重复的值map转json
// map to json
package main
import (
"encoding/json"
"fmt"
)
func main() {
s := []map[string]interface{}{}
m1 := map[string]interface{}{"name": "John", "age": 10}
m2 := map[string]interface{}{"name": "Alex", "age": 12}
s = append(s, m1, m2)
s = append(s, m2)
b, err := json.Marshal(s)
if err != nil {
fmt.Println("json.Marshal failed:", err)
return
}
fmt.Println("b:", string(b))
}切片
切片是动态数组,可以搭配结构体或map形成多重嵌套
var projects = make([]models.Project, 0)上面的
models.Project是一个结构体,前面加一个[]就变成了接片,用make生成,指定初始长度为0(必须要指定一个值,反正自动增加)。这样这个projects变量是切片,里面的数据类型是models.Project结构体
切片去重
/* 在slice中去除重复的元素,其中a必须是已经排序的序列。
* params:
* a: slice对象,如[]string, []int, []float64, ...
* return:
* []interface{}: 已经去除重复元素的新的slice对象
*/
func SliceRemoveDuplicate(a interface{}) (ret []interface{}) {
if reflect.TypeOf(a).Kind() != reflect.Slice {
fmt.Printf("<SliceRemoveDuplicate> <a> is not slice but %T\n", a)
return ret
}
va := reflect.ValueOf(a)
for i := 0; i < va.Len(); i++ {
if i > 0 && reflect.DeepEqual(va.Index(i-1).Interface(), va.Index(i).Interface()) {
continue
}
ret = append(ret, va.Index(i).Interface())
}
return ret
}测试代码:
func test_SliceRemoveDuplicate() {
slice_string := []string{"a", "b", "c", "d", "a", "b", "c", "d"}
slice_int := []int{1, 2, 3, 4, 5, 1, 2, 3, 4, 5}
slice_float := []float64{1.11, 2.22, 3.33, 4.44, 1.11, 2.22, 3.33, 4.44}
sort.Strings(slice_string)
sort.Ints(slice_int)
sort.Float64s(slice_float)
fmt.Printf("slice_string = %v, %p\n", slice_string, slice_string)
fmt.Printf("slice_int = %v, %p\n", slice_int, slice_int)
fmt.Printf("slice_float = %v, %p\n", slice_float, slice_float)
ret_slice_string := SliceRemoveDuplicate(slice_string)
ret_slice_int := SliceRemoveDuplicate(slice_int)
ret_slice_float := SliceRemoveDuplicate(slice_float)
fmt.Printf("ret_slice_string = %v, %p\n", ret_slice_string, ret_slice_string)
fmt.Printf("ret_slice_int = %v, %p\n", ret_slice_int, ret_slice_int)
fmt.Printf("ret_slice_float = %v, %p\n", ret_slice_float, ret_slice_float)
fmt.Printf("<after> slice_string = %v, %p\n", slice_string, slice_string)
fmt.Printf("<after> slice_int = %v, %p\n", slice_int, slice_int)
fmt.Printf("<after> slice_float = %v, %p\n", slice_float, slice_float)
}结果:
slice_string = [a a b b c c d d], 0xc042088000
slice_int = [1 1 2 2 3 3 4 4 5 5], 0xc04200e1e0
slice_float = [1.11 1.11 2.22 2.22 3.33 3.33 4.44 4.44], 0xc042014200
ret_slice_string = [a b c d], 0xc042034100
ret_slice_int = [1 2 3 4 5], 0xc042088080
ret_slice_float = [1.11 2.22 3.33 4.44], 0xc042034180
<after> slice_string = [a a b b c c d d], 0xc042088000
<after> slice_int = [1 1 2 2 3 3 4 4 5 5], 0xc04200e1e0
<after> slice_float = [1.11 1.11 2.22 2.22 3.33 3.33 4.44 4.44], 0xc042014200插入
/*
* 在Slice指定位置插入元素。
* params:
* s: slice对象,类型为[]interface{}
* index: 要插入元素的位置索引
* value: 要插入的元素
* return:
* 已经插入元素的slice,类型为[]interface{}
*/
func SliceInsert(s []interface{}, index int, value interface{}) []interface{} {
rear := append([]interface{}{}, s[index:]...)
return append(append(s[:index], value), rear...)
}
/*
* 在Slice指定位置插入元素。
* params:
* s: slice对象指针,类型为*[]interface{}
* index: 要插入元素的位置索引
* value: 要插入的元素
* return:
* 无
*/
func SliceInsert2(s *[]interface{}, index int, value interface{}) {
rear := append([]interface{}{}, (*s)[index:]...)
*s = append(append((*s)[:index], value), rear...)
}
/*
* 在Slice指定位置插入元素。
* params:
* s: slice对象的指针,如*[]string, *[]int, ...
* index: 要插入元素的位置索引
* value: 要插入的元素
* return:
* true: 插入成功
* false: 插入失败(不支持的数据类型)
*/
func SliceInsert3(s interface{}, index int, value interface{}) bool {
if ps, ok := s.(*[]string); ok {
if val, ok := value.(string); ok {
rear := append([]string{}, (*ps)[index:]...)
*ps = append(append((*ps)[:index], val), rear...)
return true
}
} else if ps, ok := s.(*[]int); ok {
if val, ok := value.(int); ok {
rear := append([]int{}, (*ps)[index:]...)
*ps = append(append((*ps)[:index], val), rear...)
}
} else if ps, ok := s.(*[]float64); ok {
if val, ok := value.(float64); ok {
rear := append([]float64{}, (*ps)[index:]...)
*ps = append(append((*ps)[:index], val), rear...)
}
} else {
fmt.Printf("<SliceInsert3> Unsupported type: %T\n", s)
}
return false
}说明:
- SliceInsert()方法是传入一个[]interface{}类型的slice对象,返回的也是一个[]interface{}类型的slice对象。
- SliceInsert2()方法是传入一个[]interface{}类型的slice对象指针,直接修改这个slice对象。
- SliceInsert3()方法是传入一个具体类型的slice对象指针(如[]string, []int等),方法中直接修改这个slice对象,返回操作是否成功的状态(bool)。
删除
/*
* 删除Slice中的元素。
* params:
* s: slice对象,类型为[]interface{}
* index: 要删除元素的索引
* return:
* 已经删除指定元素的slice,类型为[]interface{}
* 说明:返回的序列与传入的序列地址不发生变化(但是传入的序列内容已经被修改,不能再使用)
*/
func SliceRemove(s []interface{}, index int) []interface{} {
return append(s[:index], s[index+1:]...)
}
/*
* 删除Slice中的元素。
* params:
* s: slice对象指针,类型为*[]interface{}
* index: 要删除元素的索引
* return:
* 无
* 说明:直接操作传入的Slice对象,传入的序列地址不变,但内容已经被修改
*/
func SliceRemove2(s *[]interface{}, index int) {
*s = append((*s)[:index], (*s)[index+1:]...)
}
/*
* 删除Slice中的元素。
* params:
* s: slice对象的指针,如*[]string, *[]int, ...
* index: 要删除元素的索引
* return:
* true: 删除成功
* false: 删除失败(不支持的数据类型)
* 说明:直接操作传入的Slice对象,不需要转换为[]interface{}类型。
*/
func SliceRemove3(s interface{}, index int) bool {
if ps, ok := s.(*[]string); ok {
*ps = append((*ps)[:index], (*ps)[index+1:]...)
} else if ps, ok := s.(*[]int); ok {
*ps = append((*ps)[:index], (*ps)[index+1:]...)
} else if ps, ok := s.(*[]float64); ok {
*ps = append((*ps)[:index], (*ps)[index+1:]...)
} else {
fmt.Printf("<SliceRemove3> Unsupported type: %T\n", s)
return false
}
return true
}清空
/*
* 清空Slice,传入的slice对象地址发生变化。
* params:
* s: slice对象指针,类型为*[]interface{}
* return:
* 无
*/
func SliceClear(s *[]interface{}) {
*s = append([]interface{}{})
}
/*
* 清空Slice,传入的slice对象地址不变。
* params:
* s: slice对象指针,类型为*[]interface{}
* return:
* 无
*/
func SliceClear2(s *[]interface{}) {
*s = (*s)[0:0]
}
/*
* 清空Slice,传入的slice对象地址不变。
* params:
* s: slice对象的指针,如*[]string, *[]int, ...
* return:
* true: 清空成功
* false: 清空失败(不支持的数据类型)
*/
func SliceClear3(s interface{}) bool {
if ps, ok := s.(*[]string); ok {
*ps = (*ps)[0:0]
//*ps = append([]string{})
} else if ps, ok := s.(*[]int); ok {
*ps = (*ps)[0:0]
//*ps = append([]int{})
} else if ps, ok := s.(*[]float64); ok {
*ps = (*ps)[0:0]
//*ps = append([]float64{})
} else {
fmt.Printf("<SliceClear3> Unsupported type: %T\n", s)
return false
}
return true
}常用操作
查看程序运行时间
import "time" // 引用time库函数
start := time.Now() // 获取当前时间
// 被测代码
cost := time.Since(start) // 计算此时与start的时间差
// time.Now().Sub(start)也可查看当前go版本号
go version如果要升级版本,直接去官网下载对应的版本就好。但是会直接卸载之前的版本。环境变量一般会自动处理,关闭窗口(vscode,git bash之类的),再打开就能看到已经好了。
单引号、双引号、反引号
Golang限定字符或者字符串一共三种引号,单引号(’’),双引号(“”) 以及反引号(``)。反引号就是标准键盘“Esc”按钮下面的那个键。
单引号,表示byte类型或rune类型,对应 uint8和int32类型,默认是 rune 类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。
双引号,才是字符串,实际上是字符数组。可以用索引号访问某字节,也可以用len()函数来获取字符串所占的字节长度。
反引号,表示字符串字面量,但不支持任何转义序列。字面量 raw literal string 的意思是,你定义时写的啥样,它就啥样,你有换行,它就换行。你写转义字符,它也就展示转义字符。
反引号有时候能起到很好的作用,比如一个字符串里面有双引号,分号这种,并且分布的还不规律,用反引号括起来就好
字符串中包含双引号
反引号
str2 := `"www.hewe.vip"` fmt.Println(len(str2)) fmt.Println(str2) //输出结果 14 "www.hewe.vip"转义
str3 := "\"www.hewe.vip\"" fmt.Println(len(str3)) fmt.Println(str3) //输出结果 14 "www.hewe.vip"使用strconv包
str := strconv.Quote("www.hewe.vip") fmt.Println(len(str)) fmt.Println(str1) //输出结果 14 "www.hewe.vip"
变量类型转换
string转成int:
int, err := strconv.Atoi(string)
string转成int64:
int64, err := strconv.ParseInt(string, 10, 64)
int转成string:
string := strconv.Itoa(int)
int64转成string:
string := strconv.FormatInt(int64,10)具体例子:
package main
import (
"fmt"
"strconv"
)
func main() {
cfdversion :="100"
newcfd,_ :=strconv.Atoi(cfdversion)
fmt.Println(newcfd)
}注意事项:
1.要导入包
2.转换变量类型后要重新用一个名字,不能用之前的变量名
3.下划线那个地方是err,被省略了
判断变量类型
方法一:
package main
import (
"fmt"
)
func main() {
v1 := "123456"
v2 := 12
fmt.Printf("v1 type:%T\n", v1)
fmt.Printf("v2 type:%T\n", v2)
}
方法二:
package main
import (
"fmt"
"reflect"
)
func main() {
v1 := "123456"
v2 := 12
// reflect
fmt.Println("v1 type:", reflect.TypeOf(v1))
fmt.Println("v2 type:", reflect.TypeOf(v2))
}判断类型是否为map
if reflect.ValueOf(map1).Kind() == reflect.Map {
} else {
}json相关操作
发送json格式的http请求
发送json为参数的post请求,以结构体为载体
type RequestBody struct {
Id int `json:"id"`
Name string `json:"name"`
}
func testPost(id int, name string) {
request := RequestBody{
Id: id,
Name: name,
}
requestBody := new(bytes.Buffer)
json.NewEncoder(requestBody).Encode(request)
url := "https://test.com"
req, err := http.NewRequest("POST", url, requestBody)
req.Header.Set("Content-Type", "application/json")
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
panic(err)
}
defer resp.Body.Close()
fmt.Println("response Status:", resp.Status)
fmt.Println("response Headers:", resp.Header)
body, _ := ioutil.ReadAll(resp.Body)
fmt.Println("response Body:", string(body))
}解析json文件
package main
import (
// "bytes"
"encoding/json"
"fmt"
"io/ioutil"
// "reflect"
)
func con_var_name (key string) string {
var res string
bytes,_:=ioutil.ReadFile("C:/Users/76585/Desktop/para_compare_ver2.json")
m :=make(map[string]interface{})
err := json.Unmarshal([]byte(bytes),&m)
if err != nil {
fmt.Println("err=",err)
return ""
}
for _, value :=range m{
// fmt.Println(reflect.TypeOf(value.([]interface{})[1].(map[string]interface{})["name"]))
if key==value.([]interface{})[0].(map[string]interface{})["name"]{
res=key
return res
}
if key==value.([]interface{})[1].(map[string]interface{})["name"]{
tmp :=value.([]interface{})[0].(map[string]interface{})["name"]
res=tmp.(string)
return res
}
}
res=key
return res
}解析json文件,interface转int
因为json解析得到的数据是map[string]interface,里面的字段可能是数字,有时候需要取出来比较,
就需要将interface转为int。
需要先转为string,再用 strconv.Atoi,将string转为int。
结构体解析为json
先上代码
最为关键的是结构体里面的成员变量名,首字母必须是大写,否则无法解析,解析出来的是空。
package main
import (
"encoding/json"
"fmt"
)
type Product struct {
Name string
ProductId int64
Number int
Price float64
IsOnSale bool
}
func main() {
var p Product
// p := Product{}
p.Name="apple"
p.ProductId=1
p.Number=100
p.Price=3.45
p.IsOnSale=false
data, _ := json.Marshal(&p)
fmt.Println(string(data))
}
将json字符串解码到相应的数据结构
type StuRead struct {
Name interface{} `json:"name"`
Age interface{}
HIgh interface{}
sex interface{}
Class interface{} `json:"class"`
Test interface{}
}
type Class struct {
Name string
Grade int
}
func main() {
//json字符中的"引号,需用\进行转义,否则编译出错
//json字符串沿用上面的结果,但对key进行了大小的修改,并添加了sex数据
data:="{\"name\":\"张三\",\"Age\":18,\"high\":true,\"sex\":\"男\",\"CLASS\":{\"naME\":\"1班\",\"GradE\":3}}"
str:=[]byte(data)
//1.Unmarshal的第一个参数是json字符串,第二个参数是接受json解析的数据结构。
//第二个参数必须是指针,否则无法接收解析的数据,如stu仍为空对象StuRead{}
//2.可以直接stu:=new(StuRead),此时的stu自身就是指针
stu:=StuRead{}
err:=json.Unmarshal(str,&stu)
//解析失败会报错,如json字符串格式不对,缺"号,缺}等。
if err!=nil{
fmt.Println(err)
}
fmt.Println(stu)
}map转json
例子在前面 基本数据类型操作-》map相关操作
字符串操作
package main
import (
"fmt"
"strings"
)
func main() {
s := "smallming"
//第一次出现的索引
fmt.Println(strings.Index(s, "l"))
//最后一次出现的索引
fmt.Println(strings.LastIndex(s, "l"))
//是否以指定内容开头
fmt.Println(strings.HasPrefix(s, "small"))
//是否以指定内容结尾
fmt.Println(strings.HasSuffix(s, "ming"))
//是否包含指定字符串
fmt.Println(strings.Contains(s, "mi"))
//全变小写
fmt.Println(strings.ToLower(s))
//全大写
fmt.Println(strings.ToUpper(s))
//把字符串中前n个old子字符串替换成new字符串,如果n小于0表示全部替换.
//如果n大于old个数也表示全部替换
fmt.Println(strings.Replace(s, "m", "k", -1))
//把字符串重复count遍
fmt.Println(strings.Repeat(s, 2))
//去掉字符串前后指定字符
fmt.Println(strings.Trim(s, " ")) //去空格可以使用strings.TrimSpace(s)
//根据指定字符把字符串拆分成切片
fmt.Println(strings.Split(s, "m"))
//使用指定分隔符把切片内容合并成字符串
arr := []string{"small", "ming"}
fmt.Println(strings.Join(arr, ""))
}字符串替换
str = strings.Replace(str, " ", "", -1)func Replace(s, old, new string, n int) string
返回将s中前n个不重叠old子串都替换为new的新字符串,如果n<0会替换所有old子串
字符串处理函数
Golang中的strings包:
Count(s string, str string) int:计算字符串str在s中的非重叠个数。如果str为空串则返回s中的字符(非字节)个数+1。
Index(s string, str string) int :返回子串str在字符串s中第一次出现的位置。如果找不到则返回-1;如果str为空,则返回0。
LastIndex(s string, str string) int: 返回子串str在字符串s中最后一次出现的位置。如果找不到则返回-1;如果str为空则返回字符串s的长度。
IndexRune(s string, r rune) int :返回字符r在字符串s中第一次出现的位置。如果找不到则返回-1。
IndexAny(s string, str string) int :返回字符串str中的任何一个字符在字符串s中第一次出现的位置。如果找不到或str为空则返回-1。
LastIndexAny(s string, str string) int: 返回字符串str中的任何一个字符在字符串s中最后一次出现的位置。如果找不到或str为空则返回-1。
Contains(s string, str string) bool:判断字符串s中是否包含个子串str。包含或者str为空则返回true。
ContainsAny(s string, str string) bool:判断字符串s中是否包含个子串str中的任何一个字符。包含则返回true,如果str为空则返回false。
ContainsRune(s string, r rune) bool:判断字符串s中是否包含字符r。
SplitN(s, str string, n int) []string:以str为分隔符,将s切分成多个子串,结果中**不包含**str本身。如果str为空则将s切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。参数n表示最多切分出几个子串,超出的部分将不再切分,最后一个n包含了所有剩下的不切分。如果n为0,则返回nil;如果n小于0,则不限制切分个数,全部切分。
SplitAfterN(s, str string, n int) []string:以str为分隔符,将s切分成多个子串,结果中**包含**str本身。如果str为空,则将s切分成Unicode字符列表。如果s 中没有str子串,则将整个s作为 []string 的第一个元素返回。参数n表示最多切分出几个子串,超出的部分将不再切分。如果n为0,则返回 nil;如果 n 小于 0,则不限制切分个数,全部切分。
Split(s, str string) []string:以str为分隔符,将s切分成多个子切片,结果中**不包含**str本身。如果str为空,则将s切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。
SplitAfter(s, str string) []string:以str为分隔符,将s切分成多个子切片,结果中**包含**str本身。如果 str 为空,则将 s 切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。
Fields(s string) []string:以连续的空白字符为分隔符,将s切分成多个子串,结果中不包含空白字符本身。空白字符有:\t, \n, \v, \f, \r, ’ ‘, U+0085 (NEL), U+00A0 (NBSP) 。如果 s 中只包含空白字符,则返回一个空列表。
FieldsFunc(s string, f func(rune) bool) []string:以一个或多个满足f(rune)的字符为分隔符,将s切分成多个子串,结果中不包含分隔符本身。如果s中没有满足f(rune)的字符,则返回一个空列表。
Join(s []string, str string) string:将s中的子串连接成一个单独的字符串,子串之间用str分隔。
HasPrefix(s string, prefix string) bool:判断字符串s是否以prefix开头。
HasSuffix(s, suffix string) bool :判断字符串s是否以prefix结尾。
Map(f func(rune) rune, s string) string:将s中满足f(rune)的字符替换为f(rune)的返回值。如果f(rune)返回负数,则相应的字符将被删除。
Repeat(s string, n int) string:将n个字符串s连接成一个新的字符串。
ToUpper(s string) string:将s中的所有字符修改为其大写格式。对于非ASCII字符,它的大写格式需要查表转换。
ToLower(s string) string:将s中的所有字符修改为其小写格式。对于非ASCII字符,它的小写格式需要查表转换。
ToTitle(s string) string:将s中的所有字符修改为其Title格式,大部分字符的Title格式就是Upper格式,只有少数字符的Title格式是特殊字符。这里的ToTitle主要给Title函数调用。
TrimLeftFunc(s string, f func(rune) bool) string:删除s头部连续的满足f(rune)的字符。
TrimRightFunc(s string, f func(rune) bool) string:删除s尾部连续的满足f(rune)的字符。
TrimFunc(s string, f func(rune) bool) string:删除s首尾连续的满足f(rune)的字符。
IndexFunc(s string, f func(rune) bool) int:返回s中第一个满足f(rune) 的字符的字节位置。如果没有满足 f(rune) 的字符,则返回 -1。
LastIndexFunc(s string, f func(rune) bool) int:返回s中最后一个满足f(rune)的字符的字节位置。如果没有满足 f(rune) 的字符,则返回 -1。
Trim(s string, str string) string:删除s首尾连续的包含在str中的字符。
TrimLeft(s string, str string) string:删除s头部连续的包含在str中的字符串。
TrimRight(s string, str string) string:删除s尾部连续的包含在str中的字符串。
TrimSpace(s string) string:删除s首尾连续的的空白字符。
TrimPrefix(s, prefix string) string:删除s头部的prefix字符串。如果s不是以prefix开头,则返回原始s。
TrimSuffix(s, suffix string) string:删除s尾部的suffix字符串。如果s不是以suffix结尾,则返回原始s。(只去掉一次,注意和TrimRight区别)
Replace(s, old, new string, n int) string:返回s的副本,并将副本中的old字符串替换为new字符串,替换次数为n次,如果n为-1,则全部替换;如果 old 为空,则在副本的每个字符之间都插入一个new。
EqualFold(s1, s2 string) bool:比较UTF-8编码在小写的条件下是否相等,不区分大小写,同时它还会对特殊字符进行转换。比如将“ϕ”转换为“Φ”、将“DŽ”转换为“Dž”等,然后再进行比较。
“==”比较字符串是否相等,区分大小写,返回bool。
Compare(s1 string, s2 string) int1:比较字符串,区分大小写,比”==”速度快。相等为0,不相等为-1。正则表达式
常用的元字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束字符转义:
如果你想查找元字符本身的话,比如你查找.,或者,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用.和\。当然,要查找\本身,你也得用\\。
重复
如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
分枝条件:
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 “|” 把不同的规则分隔开。
分组:
重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作。
反义字符
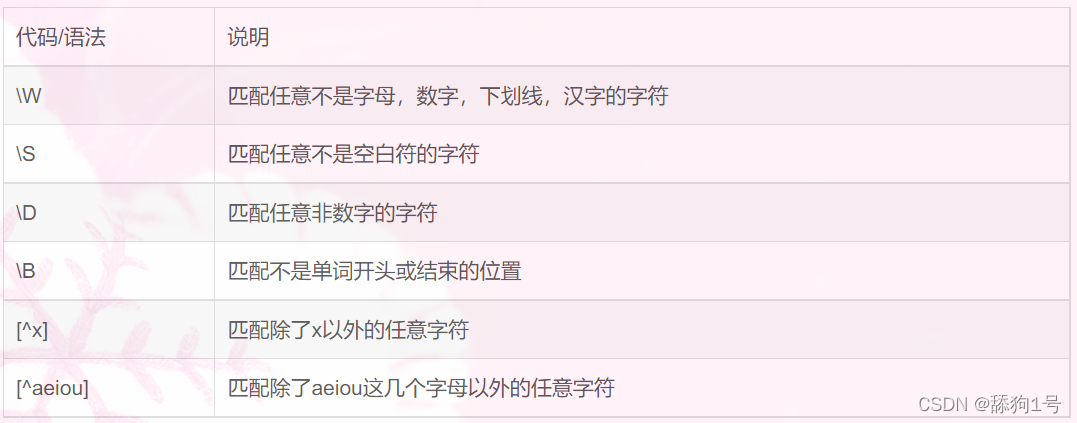
例子:\S+匹配不包含空白符的字符串。
常用的正则表达式函数:
reg = regexp.MustCompile(`匹配模式`)
reg.FindAllString( )
reg.ReplaceAllString()例子
func main() {
text := `Hello 世界!123 Go.`
// 查找连续的小写字母
reg := regexp.MustCompile(`[a-z]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["ello" "o"]
// 查找连续的非小写字母
reg = regexp.MustCompile(`[^a-z]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["H" " 世界!123 G" "."]
// 查找连续的单词字母
reg = regexp.MustCompile(`[\w]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello" "123" "Go"]
// 查找连续的非单词字母、非空白字符
reg = regexp.MustCompile(`[^\w\s]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["世界!" "."]
// 查找连续的大写字母
reg = regexp.MustCompile(`[[:upper:]]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["H" "G"]
// 查找连续的非 ASCII 字符
reg = regexp.MustCompile(`[[:^ascii:]]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["世界!"]
// 查找连续的标点符号
reg = regexp.MustCompile(`[\pP]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["!" "."]
// 查找连续的非标点符号字符
reg = regexp.MustCompile(`[\PP]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello 世界" "123 Go"]
// 查找连续的汉字
reg = regexp.MustCompile(`[\p{Han}]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["世界"]
// 查找连续的非汉字字符
reg = regexp.MustCompile(`[\P{Han}]+`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello " "!123 Go."]
// 查找 Hello 或 Go
reg = regexp.MustCompile(`Hello|Go`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello" "Go"]
// 查找行首以 H 开头,以空格结尾的字符串
reg = regexp.MustCompile(`^H.*\s`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello 世界!123 "]
// 查找行首以 H 开头,以空白结尾的字符串(非贪婪模式)
reg = regexp.MustCompile(`(?U)^H.*\s`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello "]
// 查找以 hello 开头(忽略大小写),以 Go 结尾的字符串
reg = regexp.MustCompile(`(?i:^hello).*Go`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello 世界!123 Go"]
// 查找 Go.
reg = regexp.MustCompile(`\QGo.\E`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Go."]
// 查找从行首开始,以空格结尾的字符串(非贪婪模式)
reg = regexp.MustCompile(`(?U)^.* `)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello "]
// 查找以空格开头,到行尾结束,中间不包含空格字符串
reg = regexp.MustCompile(` [^ ]*$`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// [" Go."]
// 查找“单词边界”之间的字符串
reg = regexp.MustCompile(`(?U)\b.+\b`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello" " 世界!" "123" " " "Go"]
// 查找连续 1 次到 4 次的非空格字符,并以 o 结尾的字符串
reg = regexp.MustCompile(`[^ ]{1,4}o`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello" "Go"]
// 查找 Hello 或 Go
reg = regexp.MustCompile(`(?:Hell|G)o`)
fmt.Printf("%q\n", reg.FindAllString(text, -1))
// ["Hello" "Go"]
// 查找 Hello 或 Go,替换为 Hellooo、Gooo
reg = regexp.MustCompile(`(?PHell|G)o`)
fmt.Printf("%q\n", reg.ReplaceAllString(text, "${n}ooo"))
// "Hellooo 世界!123 Gooo."
// 交换 Hello 和 Go
reg = regexp.MustCompile(`(Hello)(.*)(Go)`)
fmt.Printf("%q\n", reg.ReplaceAllString(text, "$3$2$1"))
// "Go 世界!123 Hello."
// 特殊字符的查找
reg = regexp.MustCompile(`[\f\t\n\r\v\123\x7F\x{10FFFF}\\\^\$\.\*\+\?\{\}\(\)\[\]\|]`)
fmt.Printf("%q\n", reg.ReplaceAllString("\f\t\n\r\v\123\x7F\U0010FFFF\\^$.*+?{}()[]|", "-"))
// "----------------------"
}按行读文件
注意下这里的第二个方法,读到最后字符串为空,有时候可能会报错(被坑过),加一个判断条件,判断长度是否为0。(代码里面自己已经加了)
func Readlines(filename string) {
// go 按行读取文件的方式有两种,
// 第一 将读取到的整个文件内容按照 \n 分割
// 使用bufio
// 第一种
lines, err := ioutil.ReadFile(filename)
if err != nil {
fmt.Println(err)
} else {
contents := string(lines)
lines := strings.Split(contents, "\n")
for _, line := range lines {
fmt.Println(line)
}
}
// 第二种
fd, err := os.Open(filename)
defer fd.Close()
if err != nil {
fmt.Println("read error:", err)
}
buff := bufio.NewReader(fd)
for {
data, _, eof := buff.ReadLine()
if eof == io.EOF {
break
}
if(len(data)==0){
break
}
fmt.Println(string(data))
}
}
字符串与切片的转换
package main
import (
"fmt"
"strings"
)
func main() {
s := []string{"1", "2", "3"}
ss := fmt.Sprintf(strings.Join(s, ","))
fmt.Println(ss)
slice := strings.Split(ss, ",")
fmt.Println(slice)
//r := gin.Default()
//r.GET("/", func(context *gin.Context) {
// context.JSON(http.StatusOK,gin.H{
// "message":"demo",
// })
//})
//r.Run()
}
//D:\GoProject\gin-demo>go run main.go
//1,2,3
//[1 2 3]
读写文件
打开关闭文件
import (
"fmt"
"os"
)
func main() {
// 打开文件
file, err := os.Open("e:/a.txt")
if err != nil {
fmt.Printf("打开文件出错:%v\n", err)
}
fmt.Println(file) // &{0xc00006a780}
// 关闭文件
err = file.Close()
if err != nil {
fmt.Printf("关闭文件出错:%v\n", err)
}
}读文件
法一:带缓冲
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
// 打开文件
file, err := os.Open("e:/a.txt")
if err != nil {
fmt.Printf("打开文件出错:%v\n", err)
}
// 及时关闭文件句柄
defer file.Close()
// bufio.NewReader(rd io.Reader) *Reader
reader := bufio.NewReader(file)
// 循环读取文件的内容
for {
line, err := reader.ReadString('\n') // 读到一个换行符就结束
if err == io.EOF { // io.EOF表示文件的末尾
break
}
// 输出内容
fmt.Print(line)
}
}法二:一次性读入,不适用于大文件
import (
"fmt"
"io/ioutil"
)
func main() {
// 使用 io/ioutil.ReadFile 方法一次性将文件读取到内存中
filePath := "e:/.txt"
content, err := ioutil.ReadFile(filePath)
if err != nil {
// log.Fatal(err)
fmt.Printf("读取文件出错:%v", err)
}
fmt.Printf("%v\n", content)
fmt.Printf("%v\n", string(content))
}写文件
示例1:
创建一个新文件,写入3行:”Hello World”
打开一个存在的文件,将原来的内容覆盖成新的内容,3行:”你好,世界”
打开一个存在的文件,在原来的内容基础上,追加3行:”你好,Golang”
打开一个存在的文件,将原来的内容读出显示在终端,并且追加3行:”你好,World”
import (
"bufio"
"fmt"
"os"
)
func main() {
filePath := "e:/a.txt" // 此文件事先不存在
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666) // O_CREATE 能创建文件
if err != nil {
fmt.Printf("打开文件出错:%v", err)
return
}
// 及时关闭文件句柄
defer file.Close()
// 准备写入的内容
str := "Hello World\r\n"
// 写入时,使用带缓冲方式的 bufio.NewWriter(w io.Writer) *Writer
writer := bufio.NewWriter(file)
// 使用for循环写入内容
for i := 0; i < 3; i++ {
_, err := writer.WriteString(str) // func (b *Writer) WriteString(s string) (int, error)
if err != nil {
fmt.Printf("文件写入出错:%s", err)
}
}
// 因为 writer 是带缓存的,所以需要 Flush 方法将缓冲中的数据真正写入到文件中
_ = writer.Flush()
}
将 O_CREATE 修改为 O_TRUNC 模式即可,表示:打开文件并清空内容
将 O_TRUNC 修改为 O_APPEND 模式即可,表示:打开文件并在最后追加内容
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
filePath := "e:/a.txt"
file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("打开文件出错:%v", err)
return
}
defer file.Close()
// 先读取原来文件的内容,并显示在终端
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n') // 读到一个换行符就结束
if err == io.EOF { // io.EOF表示文件的末尾
break
}
// 输出内容
fmt.Print(str)
}
// 准备写入的内容
str := "你好,World\r\n"
// 写入时,使用带缓冲方式的 bufio.NewWriter(w io.Writer) *Writer
writer := bufio.NewWriter(file)
// 使用for循环写入内容
for i := 0; i < 3; i++ {
_, err := writer.WriteString(str) // func (b *Writer) WriteString(s string) (int, error)
if err != nil {
fmt.Printf("文件写入出错:%s", err)
}
}
// 因为 writer 是带缓存的,所以需要 Flush 方法将缓冲中的数据真正写入到文件中
_ = writer.Flush()
}
4:读写模式(O_RDWR)示例二:将一个文件写道另一个文件(两个文件均存在)
import (
"fmt"
"io/ioutil"
)
func main() {
filePath1 := "e:/a.txt"
filePath2 := "e:/b.txt"
content, err := ioutil.ReadFile(filePath1)
if err != nil {
fmt.Printf("读取文件出错:%v", err)
return
}
err = ioutil.WriteFile(filePath2, content, 0666)
if err != nil {
fmt.Printf("写入文件出错:%v", err)
return
}
}替换文件某一行内容
package main
import (
"io/ioutil"
"log"
"strings"
)
func main() {
input, err := ioutil.ReadFile("C:/Users/76585/Desktop/key.hypara")
if err != nil {
log.Fatalln(err)
}
lines := strings.Split(string(input), "\n")
for i, line := range lines {
if strings.Contains(line, "nsimutask") {
lines[i] = "int nsimutask = 0;"
}
if strings.Contains(line, "string parafilename") {
lines[i] = "string parafilename = \"../bin/grid_para.hypara\";"
break
}
}
output := strings.Join(lines, "\n")
err = ioutil.WriteFile("C:/Users/76585/Desktop/key.hypara", []byte(output), 0644)
if err != nil {
log.Fatalln(err)
}
}判断文件是否存在
golang判断文件或文件夹是否存在的方法为使用 os.Stat() 函数返回的错误值进行判断:
如果返回的错误为 nil,说明文件或文件夹存在;
如果返回的错误类型使用 os.IsNotExist() 判断为 true,说明文件或文件夹不存在;
如果返回的错误为其他类型,则不确定是否存在。
package main
import (
"fmt"
"os"
)
// 判断文件或文件夹是否存在
func PathExist(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
return true, nil
}
if os.IsNotExist(err) {
return false, nil
}
return false, err
}
func main() {
filePath := "e:/a.txt"
flag, err := PathExist(filePath)
if err != nil {
fmt.Println(err)
}
fmt.Println(flag) // true
}
拷贝文件
将src的数据拷贝到dst,直到在src上到达EOF或发生错误。返回拷贝的字节数和遇到的第一个错误。
对成功的调用,返回值err为nil而非EOF,因为Copy定义为从src读取直到EOF,它不会将读取到EOF视为应报告的错误。如果src实现了WriterTo接口,本函数会调用src.WriteTo(dst)进行拷贝;否则如果dst实现了ReaderFrom接口,本函数会调用dst.ReadFrom(src)进行拷贝。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
// 将 srcFilePath 拷贝到 dstFilePath
func CopyFile(dstFilePath string, srcFilePath string) (written int64, err error) {
// 打开srcFilePath
srcFile, err := os.Open(srcFilePath)
if err != nil {
fmt.Printf("打开文件出错:%s\n", err)
return
}
defer srcFile.Close()
// 通过 bufio/NewReader,传入 srcFile,获取到 reader
reader := bufio.NewReader(srcFile)
// 打开dstFilePath
dstFile, err := os.OpenFile(dstFilePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("打开文件出错:%s\n", err)
return
}
defer dstFile.Close()
// 通过 bufio/NewWriter,传入 dstFile,获取到 writer
writer := bufio.NewWriter(dstFile)
return io.Copy(writer, reader)
}
func main() {
srcFilePath := "e:/a.mp4"
dstFilePath := "f:/b.mp4"
_, err := CopyFile(dstFilePath, srcFilePath)
if err != nil {
fmt.Printf("拷贝文件出错:%s", err)
}
fmt.Println("拷贝文件完成")
}
自己写一个函数完成拷贝文件读取文件最后一行
func ReadFile(file_name string) (info string) {
file, err := os.Open(file_name)
if err != nil {
log.Fatal(err)
}
defer file.Close()
var lineText string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
lineText = scanner.Text()
//fmt.Print(lineText)
}
return string(lineText)
}遍历目录
package main
import (
"fmt"
"os"
)
func main() {
fmt.Println("请输入一个目录的路径:")
var path string
_, _ = fmt.Scan(&path)
// 打开目录
f, err := os.OpenFile(path, os.O_RDONLY, os.ModeDir)
if err != nil {
fmt.Printf("Open file failed:%s.\n", err)
return
}
defer f.Close()
// 读取目录
info, err := f.Readdir(-1) // -1 表示读取目录中所有目录项
// 遍历返回的切片
for _, fileInfo := range info {
if fileInfo.IsDir() {
fmt.Printf("%s是一个目录\n", fileInfo.Name())
} else {
fmt.Printf("%s是一个文件\n", fileInfo.Name())
}
}
}其它
统计一个文件中含有的英文、数字、空格以及其他字符数量。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
// 定义一个结构体,用于保存统计结果
type CharCount struct {
AlphaCount int // 记录英文个数
NumCount int // 记录数字的个数
SpaceCount int // 记录空格的个数
OtherCount int // 记录其它字符的个数
}
func main() {
// 思路: 打开一个文件, 创一个 reader
// 每读取一行,就去统计该行有多少个 英文、数字、空格和其他字符
// 然后将结果保存到一个结构体
filePath := "e:/a.txt"
file, err := os.Open(filePath)
if err != nil {
fmt.Printf("打开文件出错:%s\n", err)
return
}
defer file.Close()
// 定义一个 CharCount 实例
var count CharCount
//创建一个Reader
reader := bufio.NewReader(file)
// 开始循环的读取文件的内容
for {
line, err := reader.ReadString('\n')
if err == io.EOF { // 读到文件末尾就退出
break
}
// 遍历每一行(line),进行统计
for _, v := range line {
switch {
case v >= 'a' && v <= 'z':
fallthrough // 穿透
case v >= 'A' && v <= 'Z':
count.AlphaCount++
case v >= '0' && v <= '9':
count.NumCount++
case v == ' ' || v == '\t':
count.SpaceCount++
default :
count.OtherCount++
}
}
}
// 输出统计的结果看看是否正确
fmt.Printf("字符的个数为:%v\n数字的个数为:%v\n空格的个数为:%v\n其它字符个数:%v\n",
count.AlphaCount, count.NumCount, count.SpaceCount, count.OtherCount)
}问题或其他知识
使用grpcurl
如果准备使用docker来运行,那么pull完成后,使用下面的命令:
docker run fullstorydev/grpcurl ip:"端口" list“ip”和“端口” 记得替换
map类型interface{}转换
有时候我们在map里面嵌套map
想取内存map的值就会出现以下问题
cannot range over v (type interface {})interface{} 与其他数据类型不能直接赋值
解决方法
转为map
v.(map[string] interface {})转为int
value.(int)
在目标变量后面用. 括号int- 转为map



