数据结构
哈希表
算法
解决问题的方案
算法是给人看的,代码是给机器看的。
复杂度
复杂度是用来衡量算法效率的一个指标
时间复杂度和空间复杂度,分别从运行时间和内存占用两个维度评估算法的优劣
时间复杂度
时间复杂度描述算法的运行时间随输入规模增长的趋势
核心思想:
- 不关注具体的数值:只关心输入规模n趋近无穷大时增长的趋势,例如$n^2$比$n$增长快
- 忽略常数项和低阶项,例如$3n^2+5n+100$的时间复杂度为$n^2$
- 关注最坏情况:除非特别说明,时间复杂度默认指最坏情况
空间复杂度
临时占用的存储空间随输入规模增长的趋势,同样用大O符号表示。它关注的是算法额外使用的内存(不包括输入本身的存储空间)。
环境变量
环境变量是系统变量当中的一种,就是PATH。Windows和DOS操作系统中的path环境变量,当要求系统运行一个程序而没有告诉它程序所在的完整路径时,系统除了在当前目录下面寻找此程序外,还应到path中指定的路径去找。用户通过设置环境变量,来更好的运行进程。
说白了,把可执行程序的路径放到环境变量里面,那么以后在任意的路径下就可以直接使用这个可执行程序,而不用输入绝对路径,方便。
1.在Windows中,是由可视化的窗口模式展现出来的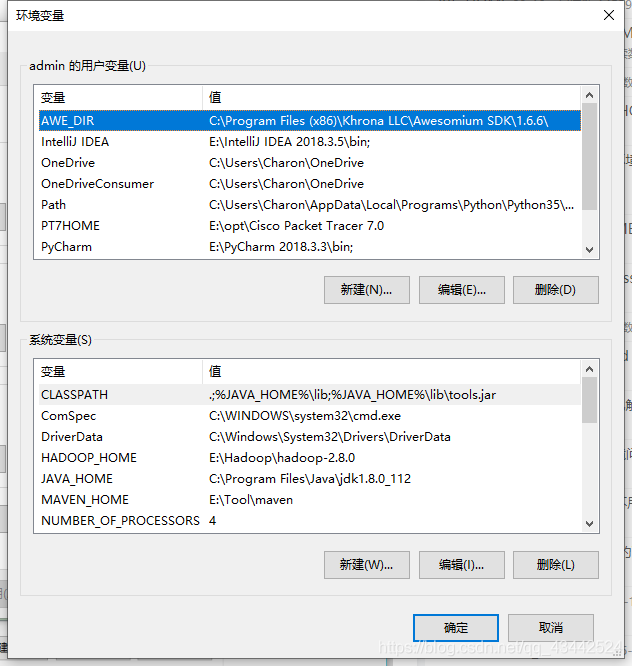
2.linux中,在 /etc/profile文件中设置
可以直接用vim进入文件进行设置,也可以用下面的语句
echo "export PATH=${PATH}:/usr/local/go/bon" >> /etc/profile最好还是用vim进行修改,用echo输入到为你文件中,会出现冗余,直接添加比较好。用冒号分隔。
修改好以后,需要更新环境变量
source /etc/profile编译
不同的语言,不同的开发环境,编译出的东西不一定一样。
比如C/C++,windows下编出的是后缀为exe的可执行程序,双击就能直接运行。但如果在linux下编出的后缀是没有exe的,是一个可运行的二进制文件。原因是因为编译器不同,linux环境的编译器一般是gcc,windows下一般是MinGW等(用VSCODE跑C一般就是这个编译器)
不过java比较特殊,因为编出来的class文件是运行在JVM上,在os上一层,与操作系统没有直接联系。所以windows编出来的class,或者打包的tar/war可以直接扔到服务器(linux)上使用(B站黑马程序员的jenkins教程—(SpringCloud微服务部署)就是这样的)
Web
Session 与 Cookie
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
Cookie机制
在程序中,会话跟踪是很重要的事情。理论上,一个用户的所有请求操作都应该属于同一个会话,而另一个用户的所有请求操作则应该属于另一个会话,二者不能混淆。例如,用户A在超市购买的任何商品都应该放在A的购物车内,不论是用户A什么时间购买的,这都是属于同一个会话的,不能放入用户B或用户C的购物车内,这不属于同一个会话。
而Web应用程序是使用HTTP协议传输数据的。HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接。这就意味着服务器无法从连接上跟踪会话。即用户A购买了一件商品放入购物车内,当再次购买商品时服务器已经无法判断该购买行为是属于用户A的会话还是用户B的会话了。要跟踪该会话,必须引入一种机制。
Cookie就是这样的一种机制。它可以弥补HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
什么是Cookie
Cookie意为“甜饼”,是由W3C组织提出,最早由Netscape社区发展的一种机制。目前Cookie已经成为标准,所有的主流浏览器如IE、Netscape、Firefox、Opera等都支持Cookie。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
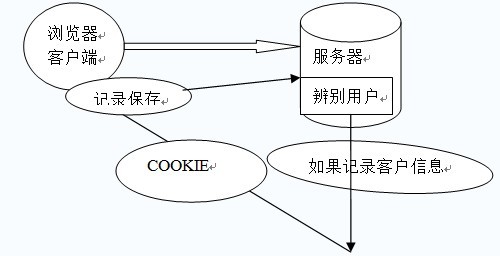
Session机制
Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力。
什么是Session
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
cookie和session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上.
简单的说,当你登录一个网站的时候,如果web服务器端使用的是session,那么所有的数据都保存在服务器上面,
客户端每次请求服务器的时候会发送 当前会话的session_id,服务器根据当前session_id判断相应的用户数据标志,以确定用户是否登录,或具有某种权限。
由于数据是存储在服务器 上面,所以你不能伪造,但是如果你能够获取某个登录用户的session_id,用特殊的浏览器伪造该用户的请求也是能够成功的。
session_id是服务器和客户端链接时候随机分配的,一般来说是不会有重复,但如果有大量的并发请求,也不是没有重复的可能性。
Session是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,会由服务器生成一个唯一的SessionID,用该SessionID 为标识符来存取服务器端的Session存储空间。而SessionID这一数据则是保存到客户端,用Cookie保存的,用户提交页面时,会将这一 SessionID提交到服务器端,来存取Session数据。这一过程,是不用开发人员干预的。所以一旦客户端禁用Cookie,那么Session也会失效。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
3、设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
4、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
5、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
密码学
MD5加密
为什么要对密码MD5
密码明文传递或者直接写到数据库中,都有被偷看的风险
为什么要对密码做两次MD5
现在存在的一些反查md5的软件,做两次为了更好的保密
整体流程如何实现
1.整体加密流程
MD5(MD5(pass明文+固定salt)+随机salt)
第一次固定salt写死在前端
第二次加密采用随机的salt 并将每次生成的salt保存在数据库中2.登录流程:
前端对用户输入的密码进行md5加密(固定的salt)
将加密后的密码传递到后端
后端使用用户id取出用户信息
后端对加密后的密码在进行md5加密(取出盐),然后与数据库中存储的密码进行对比,
ok登录成功,否则登录失败3.注册流程
前端对用户输入的密码进行md5加密(固定的salt)
将加密后的密码传递到后端
后端随机生成一个salt,
使用生成salt对前端传过来的密码进行加密,然后将加密后密码和salt一起保存到db中硬件知识
cpu 线程与进程关系
进程与线程
两种常见解释
1.进程和线程都是一个时间段的描述,是CPU工作时间段的描述。
2.进程是资源分配的最小单位,线程是CPU调度的最小单位
解释:
- CPU太快了,只有缓存存储器SRAM才能勉强追上它的速度,因此,一台机器上同时开30个程序,CPU可以把这30个程序变成顺序执行,每个只执行一小段,立马切换到下一个程序,再执行一小段,再切回来,人是无感知的。
- 一个程序准备开始执行的时候,相关资源必须要准备好,比如RAM地址,显卡,磁盘资源,这些准备好的东西打包一起就叫做上下文环境,然后CPU开始执行程序A,当然只执行了一小段时间,CPU就要切换到别的程序执行B,以保证几个程序的并发,切换之前要把A的上下文状态保存起来,下次切回来的时候接着用。
- 因此,进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文
- 进程的颗粒度太大,每次都要有上下的调入,保存,调出。线程就是进程的小分支,比如进程A有a,b,c三个线程,那么线程a,b,c就共享了进程A的上下文环境,成为了更细小的执行时间。
程序中的线程与CPU线程
看到这里会懵逼,假设一台8CPU32核的服务器,是不是跑的程序最多只能开32个线程呢?
答案当然是否定的,我们常说的进程中的线程,与CPU的线程,虽然都叫线程,但完全不是一回事。
程序的线程是软件概念,一个程序可以有多个线程,可以在一个CPU核上轮流并发执行。
CPU的线程是硬件的概念,就是核。八线程就是能让八个线程并行执行。
linux中的线程
暂时来不及总结,原文链接有。
概念
脚手架、框架、架构
- 脚手架是指一个项目模板,通过这个模板可以生成固定模板的项目。
- 框架一般是说应用框架,就是别人已经搭建好的成熟组件,我们只需要填代码就行,比如Spring
Boot就是一个框架,我们要开发spring应用,就可以在这个框架里面按照它的规范去写代码。 - 架构是指解决特定业务场景的技术解决方案。



