进程、线程、CPU
进程是系统资源分配和调度的基本单位
线程是CPU任务调度和执行的基本单位
一个进程中至少有一个线程甚至多个,线程是进程的一部分。同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
一个可执行程序可以被称为进程,比如Windows中任务管理器里面的任务,就是进程。比如打开浏览器。浏览器的进程内部可能有多个线程,如渲染线程、网络请求线程、事件处理线程等。
发展历史—早期操作系统
线程这个概念以前是没有的,以前在面对多进程任务时,采用的是并发的方式来解决。因为CPU非常快,而从硬盘读取时很慢的,所以CPU不会一直等待,而是执行别的进程
“浏览器的进程内部可能有多个线程,如渲染线程、网络请求线程、事件处理线程等。”
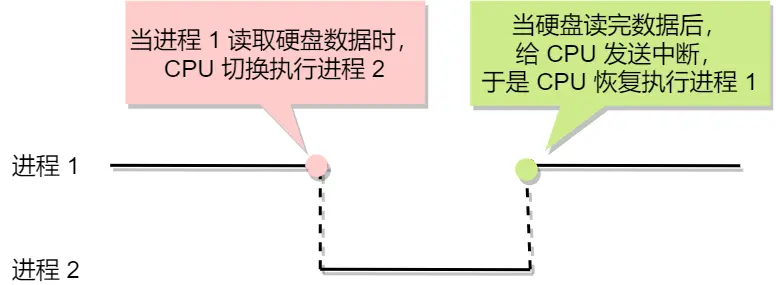
这就是早期的“多个进程、交替执行”思想。
只要切换速度够快,其实就感觉不出来,好像是在并行执行,其实是并发。
发展历史—近代操作系统
进程的局限性
- 高昂的创建/切换成本:进程需独立分配内存、文件描述符等资源,创建和上下文切换涉及大量内核操作(约需数毫秒)
- 资源共享困难:进程间通信需通过IPC机制(管道/消息队列等),数据传递效率低(例如:管道传输需两次内存拷贝)
- 响应能力受限:单进程无法同时处理多个任务(如GUI程序无法在计算时保持界面响应)
线程的核心优势
- 轻量级执行单元:线程共享进程资源,创建速度比进程快10-100倍(Linux中线程创建约需10μs)
- 高效上下文切换:同进程线程切换仅需保存寄存器(约数百时钟周期),无需TLB刷新
并发性能提升:Web服务器(如Nginx)使用线程池,可同时处理数千连接,吞吐量比进程模型提升10倍以上
- 多核利用率:8核CPU上,多线程程序可实现近线性加速(Amdahl定律),而多进程受限于通信开销
线程的引入本质是计算机体系结构发展(多核/超线程)与软件需求(高并发/低延迟)共同驱动的结果
多核cpu和多个cpu的区别
多核 CPU 和多个 CPU 有何区别? - 老狼的回答 - 知乎
https://www.zhihu.com/question/20998226/answer/705020723
多核CPU和多CPU的区别主要在于性能和成本。多核CPU性能(延迟小、带宽高)最好,但成本最高;多CPU成本小,便宜,但性能相对较差。
cpu核心数与线程数
- 一个核心只能运行一个进程/线程。如果要运行多线程,只能使用并发的方式。
- 一般来说几个核心就能并行运行几个线程,但是AMD和Intel都有各自的超线程技术,实际上一个核心能运行两个线程。‘
- 线程数并不是越多越好,超过了核心数目,部分线程就只能并发
物理 cpu 数(physical cpu)
指主板上实际插入的 cpu 硬件个数(socket)。(但是这一概念经常被泛泛的说成是 cpu 数,这很容易导致与 core 数,processor 数等概念混淆,所以此处强调是物理 cpu 数)。
由于在主板上引入多个 cpu 插槽需要更复杂的硬件支持(连接不同插槽的 cpu 到内存和其他资源),通常只会在服务器上才这样做。在家用电脑中,一般主板上只会有一个 cpu 插槽。
核心(core)
一开始,每个物理 cpu 上只有一个核心(a single core),对操作系统而言,也就是同一时刻只能运行一个进程/线程。 为了提高性能,cpu 厂商开始在单个物理 cpu 上增加核心(实实在在的硬件存在),也就出现了双核心 cpu(dual-core cpu)以及多核心 cpu(multiple cores),这样一个双核心 cpu 就是同一时刻能够运行两个进程/线程的。
同时多线程技术(simultaneous multithreading)和 超线程技术(hyper–threading/HT)
本质一样,是为了提高单个 core 同一时刻能够执行的多线程数的技术(充分利用单个 core 的计算能力,尽量让其“一刻也不得闲”)。
simultaneous multithreading 缩写是 SMT,AMD 和其他 cpu 厂商的称呼。 hyper–threading 是 Intel 的称呼,可以认为 hyper–threading 是 SMT 的一种具体技术实现。
在类似技术下,产生了如下等价术语:
- 虚拟 core: virtual core
- 逻辑 processer: logical processor
- 线程:thread
所以可以这样说:某款采用 SMT 技术的 4 核心 AMD cpu 提供了 8 线程同时执行的能力;某款采用 HT 技术的 2 核心 Intel cpu 提供了 4 线程同时执行的能力。
查看 cpu 信息
1.linux系统:
//法一
lscpuCPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2//法二
cat /proc/cpuinfoprocessor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz
stepping : 3
microcode : 0x22
cpu MHz : 2393.631
cache size : 6144 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
...
其中有几个physical id,机器上就安装了几个物理CPU
cpu core记录了每个物理CPU,内部有几个物理核
siblings 代表每个物理CPU有多少个逻辑核
2.windows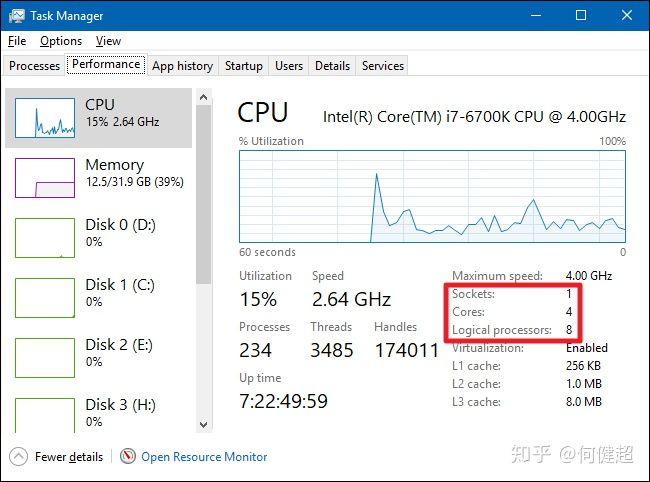
多线程程序线程数
为了让我们的多线程程序更好的利用 cpu 资源,我们通常会先了解机器拥有的 processor 数,有若干手段可以获取这一信息:
- cpuinfo 中查看:比如上文中的 cat /proc/cpuinfo | grep “processor” | wc -l
- top 命令查看:cpu0,cpu1,…
- 编程:比如在 Java 中用 Runtime.getRuntime().availableProcessors()
具体在多线程程序中设置线程数多大,对计算密集型的程序有的建议是 processor count + 1,有的建议是 processor count 的 1.5 倍,都是经验值,实测为准。
小结
- 一台完整的计算机可能包含一到多个物理 cpu
- 从单个物理 cpu (physical cpu)的角度看,其可能是单核心、双核心甚至多核心的
- 从单个核心(core)的角度看,还有 SMT / HT 等技术让每个 core 对计算机操作系统而言用起来像多个物理 core 差不多
总的逻辑 cpu 数 = 物理 cpu 数 每颗物理 cpu 的核心数 每个核心的超线程数
操作系统
基本概念+主要功能
操作系统是管理硬件和软件资源的程序
主要包括:
- 资源管理:
- 硬件资源:管理CPU、内存、存储设备、输入输出设备等。
- 软件资源:协调应用程序对资源的访问(如文件、网络等)。
- 进程管理:
- 负责进程的创建、调度、终止,确保多任务高效执行(如时间片轮转)。
- 内存管理:
- 通过虚拟内存技术分配和回收内存,实现内存保护和地址映射。
- 文件系统管理:
- 组织和管理文件存储(如文件读写、权限控制)。
- 用户接口:
- 提供命令行(如Linux的Shell)或图形界面(如Windows的桌面)供用户交互。
- 设备驱动管理:
- 通过驱动程序与硬件通信(如显卡、声卡)
层次结构
- 硬件层:物理设备(CPU、内存、硬盘等)。
- 内核层(Kernel Space):
- 操作系统的核心部分,运行在内核态(高权限),直接管理硬件资源。
- 负责进程调度、内存分配、设备驱动等基础功能。
- 系统调用接口层:
- 用户程序通过系统调用(如open()、read())请求内核服务。
- 用户层(User Space):
- 运行应用程序、库文件和工具(如浏览器、文字处理软件)。
- 通过库函数(如C标准库)间接调用内核功能。
内核
基本概念
内核(Kernel)是操作系统的核心组件,是系统启动后加载到内存中的第一个程序,始终驻留内存直到系统关闭。它是操作系统与硬件之间的直接接口,负责最底层的资源控制。
主要任务
- 进程调度:
- 决定哪个进程获得CPU使用权,分配时间片(如Linux的CFS完全公平调度器)。
- 内存管理:
- 管理物理内存和虚拟内存,实现进程间的内存隔离和保护。
- 文件系统管理:
- 通过虚拟文件系统(VFS)支持多种文件系统(如ext4、NTFS)。
- 设备驱动管理:
- 为硬件设备提供统一接口(如显卡驱动、网络驱动)。
- 系统调用处理:
- 将用户程序的请求(如文件读写)转换为硬件操作。
- 中断和异常处理:
- 处理硬件中断(如键盘输入)和软件异常(如除零错误)。
用户态和内核态
早期操作系统,线程管理由用户空间的线程库实现,这些线程就是用户态线程。
- 优点:创建/销毁成本低,切换快,适合轻量级任务。
- 致命缺陷:
- 无法利用多核:内核只调度进程,无法感知用户线程。因此,同一进程的多个用户线程只能并发(单核)或受限并行(依赖内核线程)。
- 阻塞导致进程崩溃:若一个用户线程执行系统调用(如read())进入内核态,整个进程会被阻塞,其他用户线程无法运行。
- 无内核调度支持:用户线程的调度由应用程序自行实现,容易因调度不合理导致性能问题。
后面就诞生了内核态线程
用户态线程由用户空间的线程库(如Glibc的Pthreads)管理,完全运行在用户态,内核对其不可见。
内核态线程由操作系统内核直接管理,每个内核线程在内核中有独立的线程控制块(TCB),运行在内核态或用户态(根据代码位置)。
用户线程本身无法直接获得CPU时间片,必须通过绑定内核线程才能运行。
绑定的意义
解决阻塞问题:通过内核线程的独立调度,避免用户线程阻塞导致进程崩溃。
利用多核资源:内核线程可分配到不同CPU核心,用户线程通过绑定实现并行。
中断
为什么需要中断
在计算机发展的早期阶段,CPU 是串行执行指令的,也就是说,它只能按照程序的顺序一条条地执行指令。如果 CPU 需要与外部设备(比如键盘、硬盘)交互,传统的方式是 轮询(Polling):CPU 不断检查设备的状态,直到设备准备好数据为止。
例如:
- 当用户按下键盘上的一个键时,CPU 会不断循环检查键盘是否有输入。
- 如果用户没按任何键,CPU 就在空转,白白浪费资源。
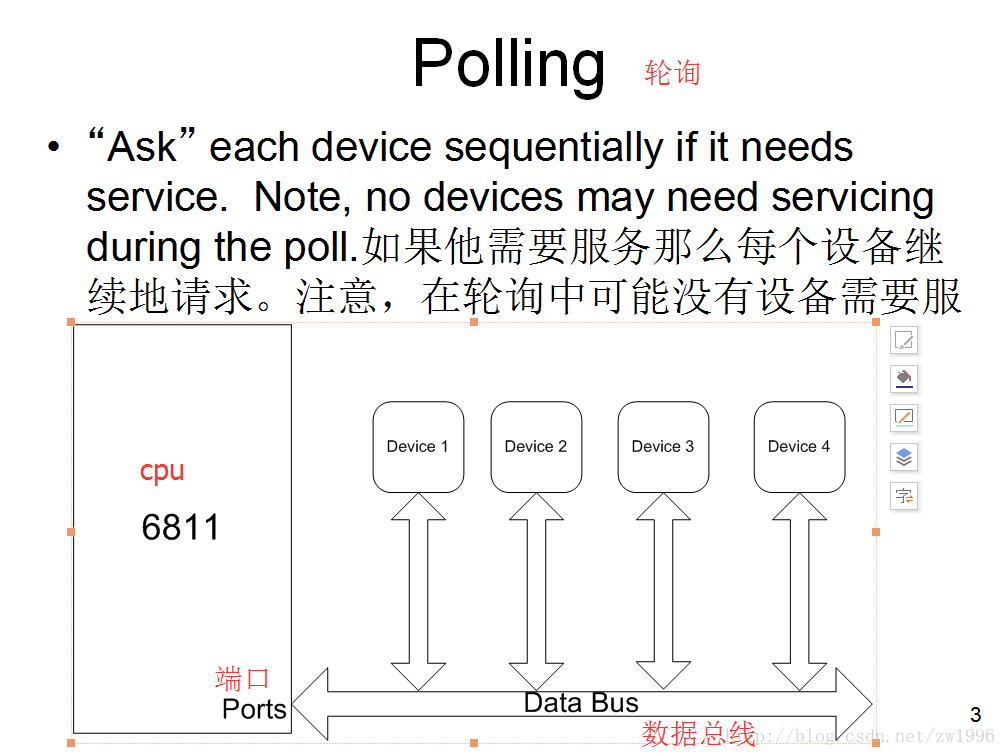
问题在于:
- 效率低:CPU 必须持续检查设备状态,即使设备长时间未就绪。
- 实时性差:如果 CPU 正在执行其他任务,可能无法及时响应设备请求。
- 硬件限制:多个设备同时请求时,轮询难以协调优先级。
为了解决这些问题,提出了“中断机制”,核心思想是:
让设备主动通知 CPU:“我准备好了,请帮我处理!”
中断的定义
计算机系统中的一种 异步通信机制。当某个事件发生时(比如键盘输入、定时器超时、硬盘读取完成),硬件或软件会向 CPU 发送一个信号,要求 CPU 暂停当前任务,转而处理这个事件。处理完成后,CPU 继续执行原任务。
中断流程
中断的处理过程分为以下几个步骤:
- 中断请求(Interrupt Request, IRQ)
- 设备通过专用的硬件线路(如中断请求线)向 CPU 发送信号。
- 例如:键盘按下时,键盘控制器通过 IRQ1 向 CPU 发出中断请求。
- 中断响应(Interrupt Response)
- CPU 在满足条件时(如当前指令执行完毕、中断未被屏蔽),暂停当前任务。
- 保存当前程序的上下文(如程序计数器、寄存器状态)到堆栈中。
- 中断服务程序(Interrupt Service Routine, ISR)
- CPU 根据中断类型号查找对应的中断服务程序入口地址(通过中断向量表)。
- 执行 ISR 处理中断事件(如读取键盘输入的数据)。
- 中断返回(Interrupt Return)
- ISR 执行完毕后,恢复之前保存的上下文。
- CPU 返回到被中断的任务,继续执行。
中断分类
- 硬件中断
- 来自外部设备(如键盘、鼠标、硬盘)。
- 可屏蔽中断:可通过 CPU 的中断屏蔽寄存器(IF 标志)控制是否响应。例如普通外设中断。
- 不可屏蔽中断(NMI):必须立即处理,通常用于严重错误(如电源掉电、奇偶校验错误)。
- 软件中断
- 由程序指令触发,常用于系统调用(如 int 0x80 在 Linux 中调用内核功能)。
实际例子
假设你按下键盘上的一个键,以下是完整的中断处理流程:
- 中断请求
- 键盘控制器检测到按键事件,通过 IRQ1 向 CPU 发送中断请求。
- 中断响应
- CPU 完成当前指令后,检查到 IRQ1 请求(未被屏蔽),暂停当前任务。
- 保存当前程序的上下文(如程序计数器 EIP、寄存器 EAX, EBX 等)到堆栈。
- 执行中断服务程序
- CPU 查找中断向量表,找到 IRQ1 对应的 ISR 地址(如 0x0009)。
- 执行 ISR:读取键盘缓冲区中的字符数据,并将其传递给操作系统(如 Windows 的键盘驱动程序)。
- 中断返回
- ISR 执行完毕后,恢复堆栈中的上下文(如 EIP, EAX, EBX)。
- CPU 返回到原来的任务,继续执行程序。
cpu工作流程
CPU的根本任务就是执行指令,对计算机来说最终都是一串由“0”和“1”组成的序列。CPU从逻辑上可以划分成3个模块,分别是控制单元、运算单元和存储单元,这三部分由CPU内部总线连接起来。如下所示:
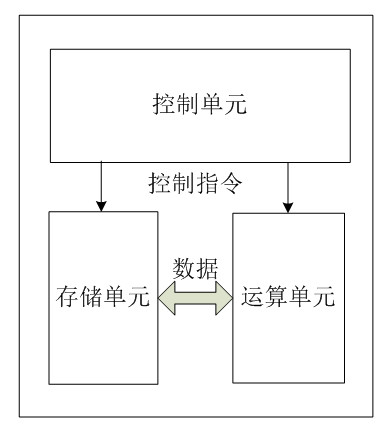
控制单元:控制单元是整个CPU的指挥控制中心,由程序计数器PC(Program Counter), 指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)等,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要包括节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
运算单元:是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
存储单元:包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。但因为受到芯片面积和集成度所限,寄存器组的容量不可能很大。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别寄存相应的数据。而通用寄存器用途广泛并可由程序员规定其用途,通用寄存器的数目因微处理器而异。这个是我们以后要介绍这个重点,这里先提一下。
CPU的运行原理(简洁版):
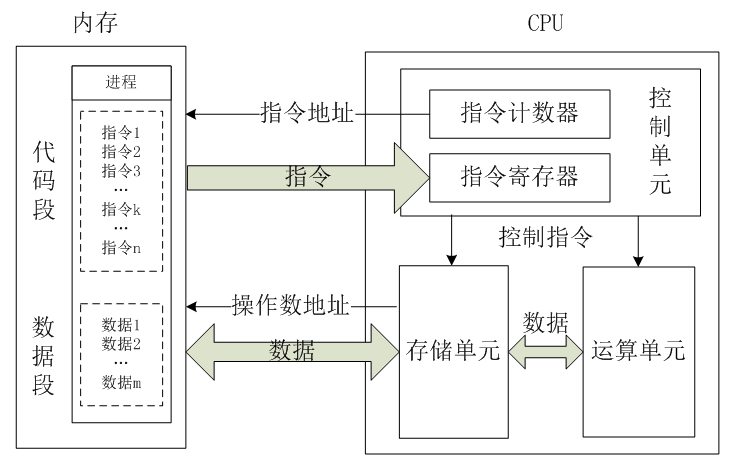
取指令:CPU的控制器从内存读取一条指令并放入指令寄存器。指令的格式一般是这个样子滴:

指令译码:指令寄存器中的指令经过译码,决定该指令应进行何种操作(就是指令里的操作码)、操作数在哪里(操作数的地址)。
执行指令,分两个阶段“取操作数”和“进行运算”。
修改指令计数器,决定下一条指令的地址。
指令周期、CPU周期、时钟周期
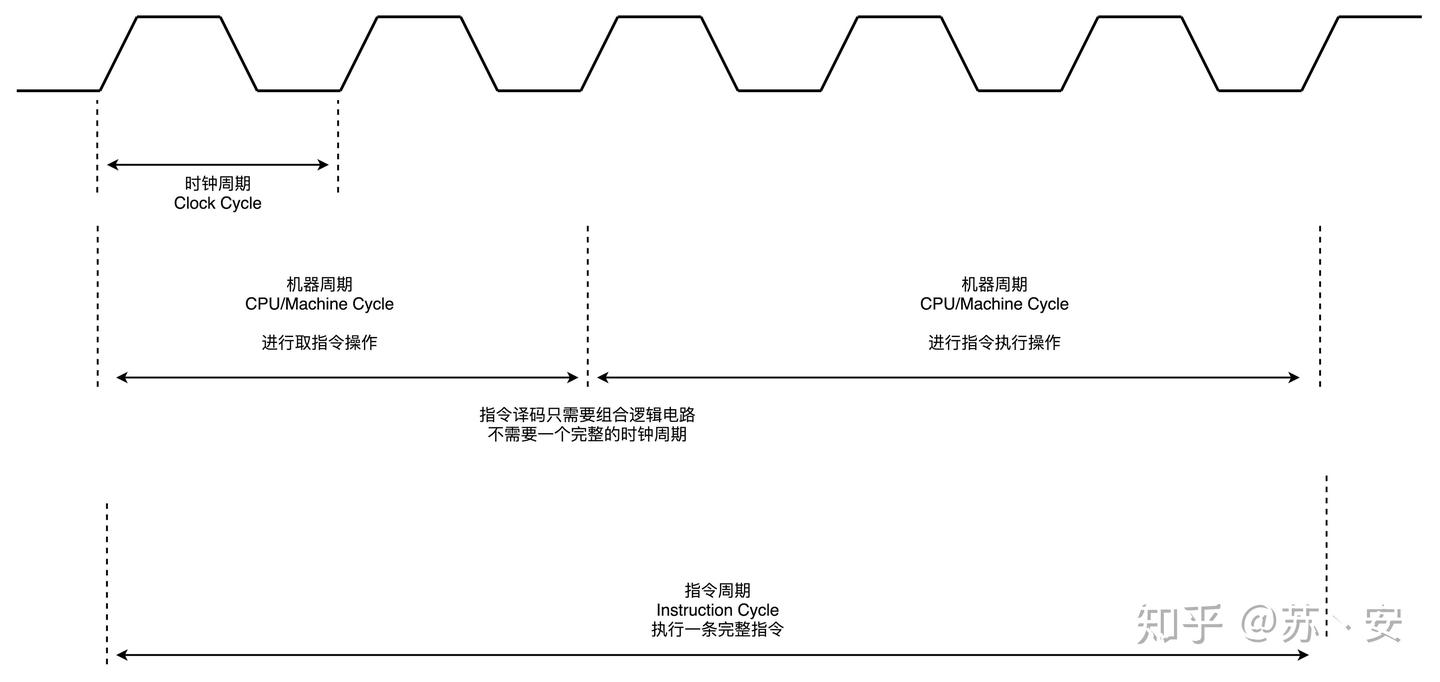
一个指令周期,包含多个 CPU 周期,而一个 CPU 周期包含多个时钟周期。
指令周期:是指计算机从取指到指令执行完毕的时间
计算机执行指令的过程可以分为以下三个步骤:
- Fetch(取指),也就是从 PC 寄存器里找到对应的指令地址,根据指令地址从内存里把具体的指令,加载到指令寄存器中,然后把 PC 寄存器自增,好在未来执行下一条指令。
- Decode(译码),也就是根据指令寄存器里面的指令,解析成要进行什么样的操作,是 R、I、J 中的哪一种指令,具体要操作哪些寄存器、数据或者内存地址。
- Execute(执行指令),也就是实际运行对应的 R、I、J 这些特定的指令,进行算术逻辑操作、数据传输或者直接的地址跳转。
取指令、存储器读、存储器写等,这每一项工作称为一个基本操作(注意:每一个基本操作都是由若干CPU最基本的动作组成)。完成一个基本操作所需要的时间称为机器周期。通常用内存中读取一个指令字的最短时间来规定CPU周期。
时钟周期也称为振荡周期,定义为时钟频率的倒数。时钟周期是计算机中最基本的、最小的时间单位。每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期。
微机设计
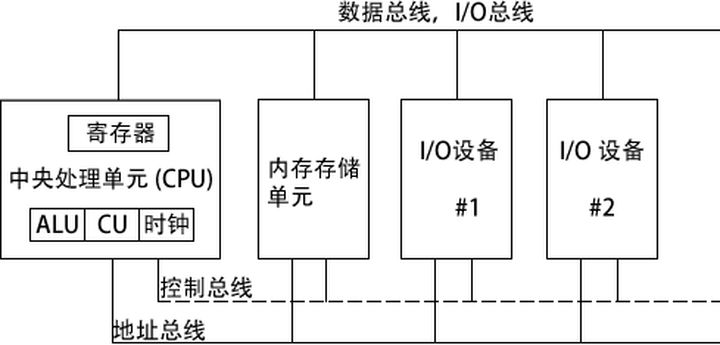
其中:
- 时钟 (clock) 对 CPU 内部操作与系统其他组件进行同步。
- 控制单元 (control unit, CU) 协调参与机器指令执行的步骤序列。
- 算术逻辑单元 (arithmetic logic unit, ALU) 执行算术运算,如加法和减法,以及逻辑运算,如 AND(与)、OR(或)和 NOT(非)。
CPU 通过主板上 CPU 插座的引脚与计算机其他部分相连。大部分引脚连接的是数据总线、控制总线和地址总线。
内存存储单元 (memory storage unit) 用于在程序运行时保存指令与数据。它接受来自 CPU 的数据请求,将数据从随机存储器 (RAM) 传输到 CPU,并从 CPU 传输到内存。
由于所有的数据处理都在 CPU 内进行,因此保存在内存中的程序在执行前需要被复制到 CPU 中。程序指令在复制到 CPU 时,可以一次复制一条,也可以一次复制多条。
总线 (bus) 是一组并行线,用于将数据从计算机一个部分传送到另一个部分。一个计算机系统通常包含四类总线:数据类、I/O 类、控制类和地址类。
数据总线 (data bus) 在 CPU 和内存之间传输指令和数据。I/O 总线在 CPU 和系统输入 / 输出设备之间传输数据。控制总线 (control bus) 用二进制信号对所有连接在系统总线上设备的行为进行同步。当前执行指令在 CPU 和内存之间传输数据时,地址总线 (address bus) 用于保持指令和数据的地址。
时钟与 CPU 和系统总线相关的每一个操作都是由一个恒定速率的内部时钟脉冲来进行同步。机器指令的基本时间单位是机器周期 (machine cycle) 或时钟周期 (clock cycle)。
时钟周期持续时间用时钟速度的倒数来计算,而时钟速度则用每秒振荡数来衡量。例如,一个每秒振荡 10 亿次 (1GHz) 的时钟,其时钟周期为 10 亿分之 1 秒 (1 纳秒 )。(CPU主频)
执行一条机器指令最少需要 1 个时钟周期,有几个需要的时钟则超过了 50 个(比如 8088 处理器中的乘法指令)。由于在 CPU、系统总线和内存电路之间存在速度差异,因此,需要访问内存的指令常常需要空时钟周期,也被称为等待状态 (wait states)。
指令执行周期
原文链接
一条机器指令不会神奇地一下就执行完成。CPU 在执行一条机器指令时,需要经过一系列预先定义好的步骤,这些步骤被称为指令执行周期 (instruction execution cycle)。
假设现在指令指针寄存器中已经有了想要执行指令的地址,下面就是执行步骤:
1) CPU 从被称为指令队列 (instruction queue) 的内存区域取得指令,之后立即增加指令指针的值。
2) CPU 对指令的二进制位模式进行译码。这种位模式可能会表示该指令有操作数(输入值)。
3) 如果有操作数,CPU 就从寄存器和内存中取得操作数。有时,这步还包括了地址计算。
4) 使用步骤 3 得到的操作数,CPU 执行该指令。同时更新部分状态标志位,如零标志 (Zero)、进位标志 (Carry) 和溢出标志 (Overflow)。
5) 如果输出操作数也是该指令的一部分,则 CPU 还需要存放其执行结果。
通常将上述听起来很复杂的过程简化为三个步骤:取指 (Fetch)、译码 (Decode) 和执行 (Execute)。操作数 (operand) 是指操作过程中输入或输出的值。例如,表达式 Z=X+Y 有两个输入操作数 (X 和 Y),—个输岀操作数 (Z)。
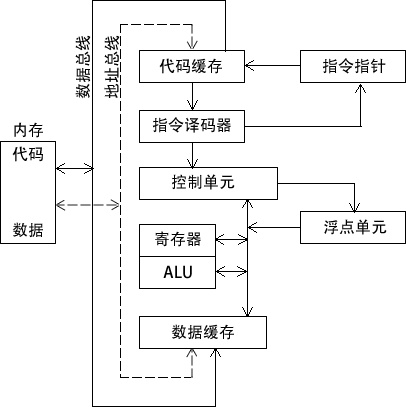
下图是一个典型 CPU 中的数据流框图。该图表现了在指令执行周期中相互交互部件之间的关系。在从内存读取程序指令之前,将其地址放到地址总线上。然后,内存控制器将所需代码送到数据总线上,存入代码高速缓存 (code cache)。指令指针的值决定下一条将要执行的指令。指令由指令译码器分析,并产生相应的数值信号送往控制单元,其协调 ALU 和浮点单元。虽然图中没有画出控制总线,但是其上传输的信号用系统时钟协调不同 CPU 部件之间的数据传输。
缓存
原文链接
作为一个常见现象,计算机从内存读取数据比从内部寄存器读取速度要慢很多。这是因为从内存读取一个值,需要经过下述步骤:
将想要读取的值的地址放到地址总线上。
设置处理器 RD(读取)引脚(改变 RD 的值)。
等待一个时钟周期给存储器芯片进行响应。
将数据从数据总线复制到目标操作数。
上述每一步常常只需要一个时钟周期,时钟周期是基于处理器内固定速率时钟节拍的一种时间测量方法。计算机的 CPU 通常是用其时钟速率来描述。例如,速率为 1.2GHz 意味着时钟节拍或振荡为每秒 12 亿次。
因此,考虑到每个时钟周期仅为 1/1 200 000 000 秒,4 个时钟周期也是非常快的。但是,与 CPU 寄存器相比,这个速度还是慢了,因为访问寄存器一般只需要 1 个时钟周期。
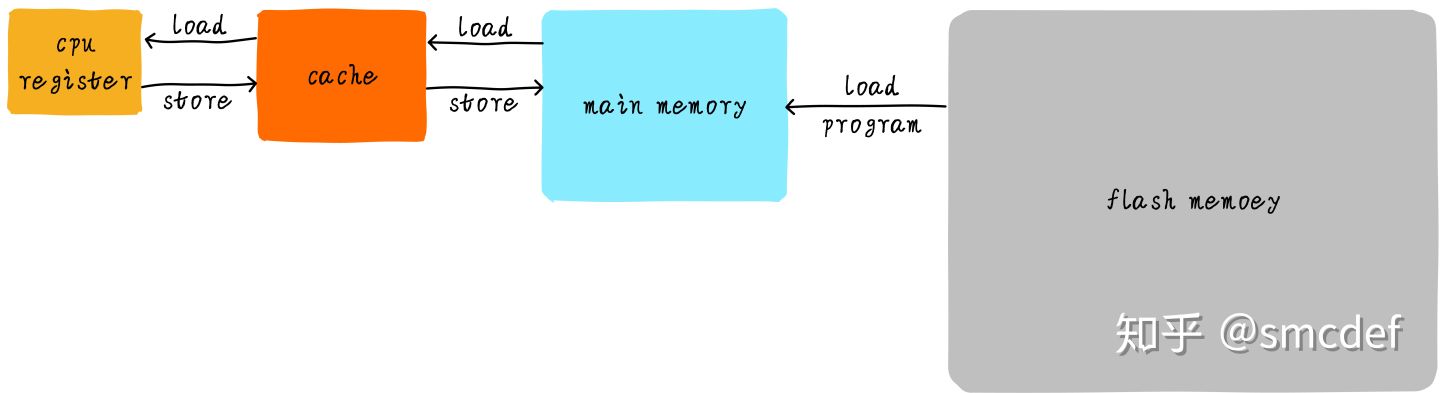
CPU和主存之间直接数据传输的方式转变成CPU和cache之间直接数据传输。cache负责和主存之间数据传输。
加载并执行程序
在程序执行之前,需要用一种工具程序将其加载到内存,这种工具程序称为程序加载器 (program loader)。加载后,操作系统必须将 CPU 指向程序的入口,即程序开始执行的地址。以下步骤是对这一过程的详细分解。
1) 操作系统(OS)在当前磁盘目录下搜索程序的文件名。如果找不到,则在预定目录列表(称为路径(path))下搜索文件名。当 OS 无法检索到文件名时,它会发出一个出错信息。
2) 如果程序文件被找到,OS 就访问磁盘目录中的程序文件基本信息,包括文件大小,及其在磁盘驱动器上的物理位置。
3) OS 确定内存中下一个可使用的位置,将程序文件加载到内存。为该程序分配内存块,并将程序大小和位置信息加入表中(有时称为描述符表(descriptor table))。另外,OS 可能调整程序内指针的值,使得它们包括程序数据地址。
4) OS 开始执行程序的第一条机器指令(程序入口)。当程序开始执行后,就成为一个进程(process)。OS 为这个进程分配一个标识号(进程 ID),用于在执行期间对其进行追踪。
5) 进程自动运行。OS 的工作是追踪进程的执行,并响应系统资源的请求。这些资源包括内存、磁盘文件和输入输出设备等。
6) 进程结束后,就会从内存中移除。
不论使用哪个版本的 Microsoft Windows,按下 Ctrl-Alt-Delete 组合键,可以选择任务管理器(task manager)选项。在任务管理器窗口可以查看应用程序和进程列表。
应用程序列表中列出了当前正在运行的完整程序名称,比如,Windows 浏览器,或者 Microsoft Visual C++。如果选择进程列表,则会看见一长串进程名。其中的每个进程都是一个独立于其他进程的,并处于运行中的小程序。
可以连续追踪每个进程使用的 CPU 时间和内存容量。在某些情况下,选定一个进程名称后,按下 Delete 键就可以关闭该进程。
指令
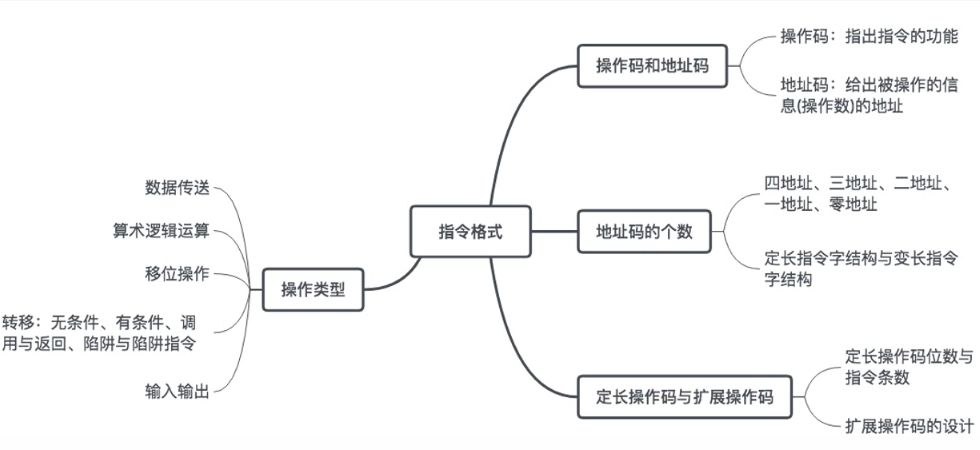
- 一条指令就是机器语言的一个语句,它是一组有意义的二进制代码。
- 一台计算机的所有指令的集合构成该机的指令系统,也称为指令集。
指令的格式
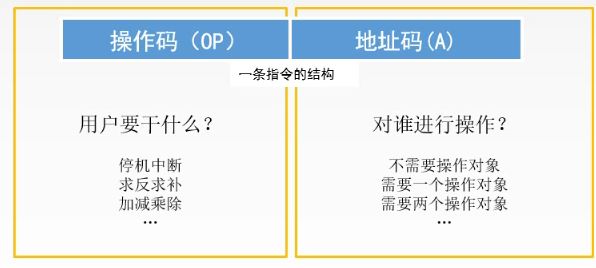
从最基本的结构上来说:一条指令通常要包括操作码字段和地址码字段两部分:
操作码字段告诉用户做什么操作?
地址码告诉用户对谁操作?
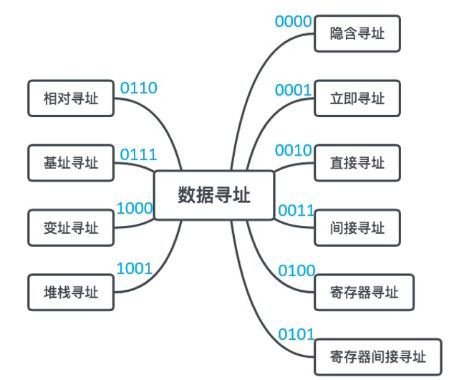
寻址方式
指令寻址的方式包括两部分:
一种是指令的寻址
(是不是很晕?指令寻址怎么又包括指令寻址。hh因为这里的指令寻址指的是具体的操作码上发出的指令。是狭义上的指令寻址。)
另一种是数据的寻址(可以理解为地址码上操作数的地址寻址)

指令寻址方式
程序执行跳转指令,将程序计数器中的数据改为7。
- 顺序寻址
从0开始执行,我们就需要在pc中写入地址0。执行完零号指令后,由于这是普通的取数指令,因此程序计数器自动+1,于是cpu开始执行指令1。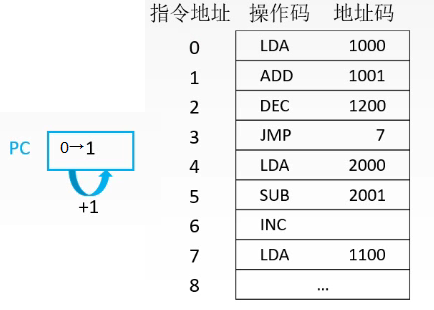
- 跳转寻址
知道碰到跳转指令,也就是指令3,程序执行跳转指令,将程序计数器中的数据改为7。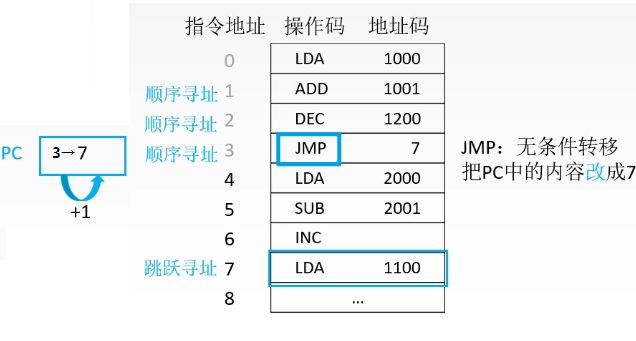
数据寻址方式