参考资料:
https://zhouyifan.net/2022/11/12/20220925-Transformer/
https://zhuanlan.zhihu.com/p/505105707
Transformer的诞生
总结:机器翻译领域,过去都是用RNN或基于RNN的架构来处理。但是RNN本轮的输入状态取决于上一轮的输出状态,这使RNN的计算必须串行执行。因此,RNN的训练通常比较缓慢。
RNN的发展历史
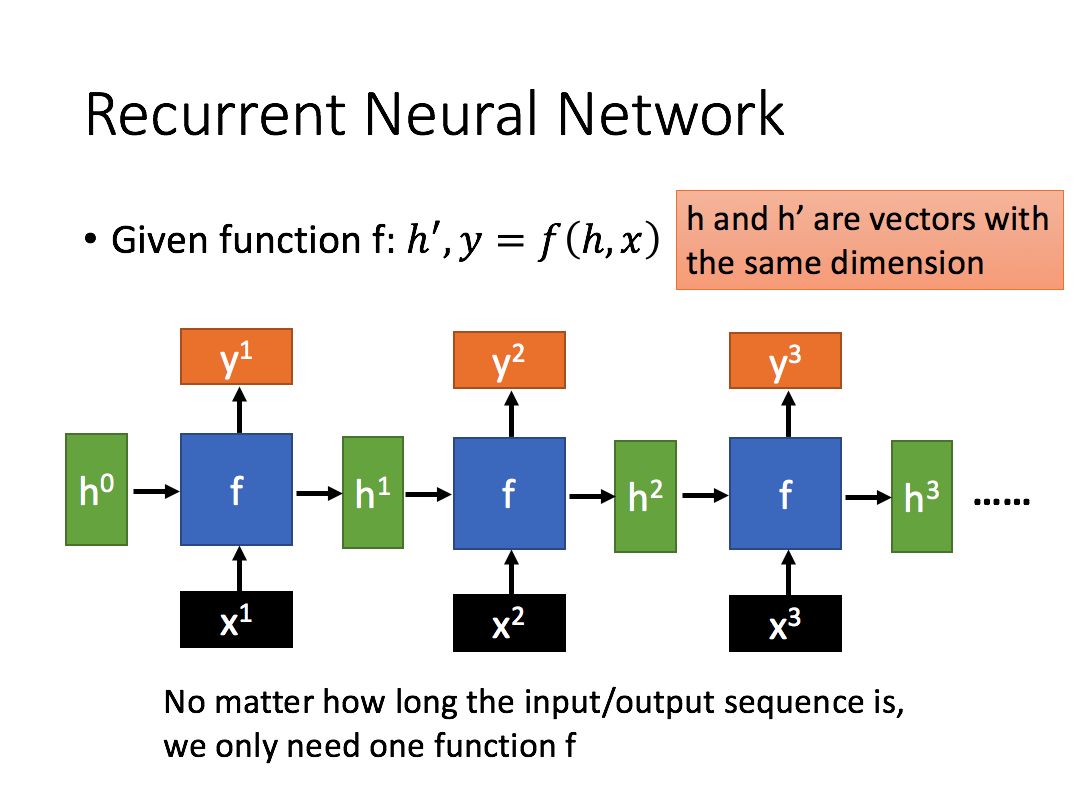
RNN的循环机制使得上一时间步产生的结果, 能够作为当下时间步输入的一部分,能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等。
传统RNN的缺陷
这种简单的RNN架构仅适用于输入和输出等长的任务。然而,大多数情况下,机器翻译的输出和输入都不是等长的。因此,人们使用了一种新的架构。前半部分的RNN只有输入,后半部分的RNN只有输出(上一轮的输出会当作下一轮的输入以补充信息)。
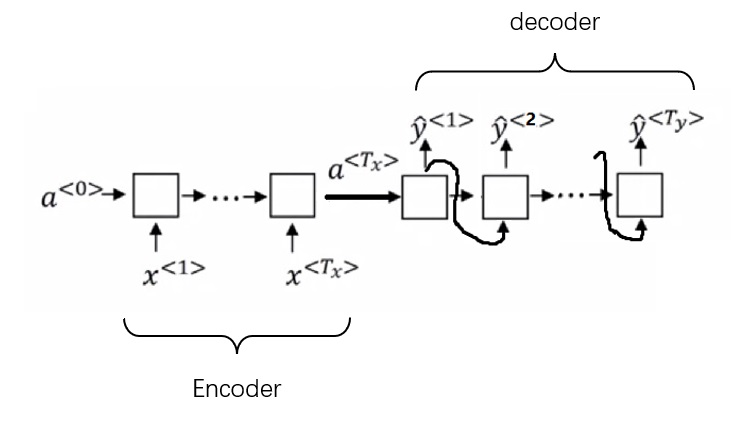
传统encoder-decoder的缺陷
但是这种架构存在不足:编码器和解码器之间只通过一个隐状态来传递信息。在处理较长的文章时,这种架构的表现不够理想。
为此,有人提出了基于注意力的架构。这种架构依然使用了编码器和解码器,只不过解码器的输入是编码器的状态的加权和,而不再是一个简单的中间状态。每一个输出对每一个输入的权重叫做注意力,注意力的大小取决于输出和输入的相关关系。这种架构优化了编码器和解码器之间的信息交流方式,在处理长文章时更加有效。
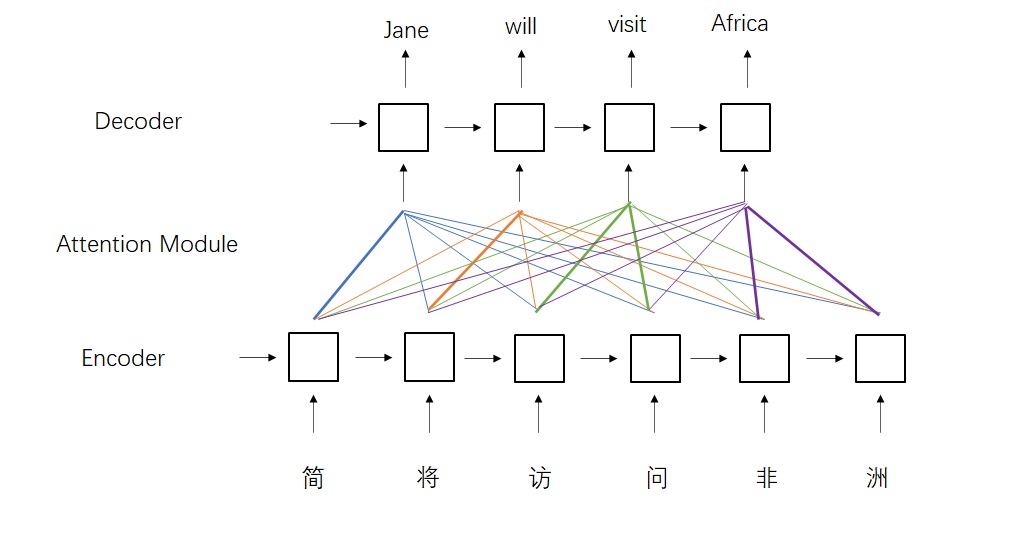
即便如此,因为依赖上一轮的输出状态,还是只能串行,所以RNN的训练通常比较慢。
Transformer的设计动机
- 提升训练的并行度
- 规避RNN的使用,完全使用注意力机制来捕捉序列之间的依赖关系
注意力机制
注意力计算的例子
“注意力“这个名字取得非常不易于理解。这个机制应该叫做“全局信息查询”。
做一次“注意力”计算,其实就跟去数据库了做了一次查询一样。假设,我们现在有这样一个以人名为key(键),以年龄为value(值)的数据库:
{
张三: 18,
张三: 20,
李四: 22,
张伟: 19
}现在,我们有一个query(查询),问所有叫“张三”的人的年龄平均值是多少。让我们写程序的话,我们会把字符串“张三”和所有key做比较,找出所有“张三”的value,把这些年龄值相加,取一个平均数。这个平均数是(18+20)/2=19。
但是,很多时候,我们的查询并不是那么明确。比如,我们可能想查询一下所有姓张的人的年龄平均值。这次,我们不是去比较key == 张三,而是比较key[0] == 张。这个平均数应该是(18+20+19)/3=19。
或许,我们的查询会更模糊一点,模糊到无法用简单的判断语句来完成。因此,最通用的方法是,把query和key各建模成一个向量。之后,对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。这样,不管多么抽象的查询,我们都可以把query, key建模成向量,用向量相似度代替查询的判断语句,用加权和代替直接取值再求平均值。“注意力”,其实指的就是这里的权重。
把这种新方法套入刚刚那个例子里。我们先把所有key建模成向量,可能可以得到这样的一个新数据库:
{
[1, 2, 0]: 18, # 张三
[1, 2, 0]: 20, # 张三
[0, 0, 2]: 22, # 李四
[1, 4, 0]: 19 # 张伟
}假设key[0]==1表示姓张。我们的查询“所有姓张的人的年龄平均值”就可以表示成向量[1, 0, 0]。用这个query和所有key算出的权重是:
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [0, 0, 2]) = 0
dot([1, 0, 0], [1, 4, 0]) = 1之后,我们该用这些权重算平均值了。注意,算平均值时,权重的和应该是1。因此,我们可以用softmax把这些权重归一化一下,再算value的加权和。
softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]
dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19这样,我们就用向量运算代替了判断语句,完成了数据库的全局信息查询。那三个1/3,就是query对每个key的注意力。
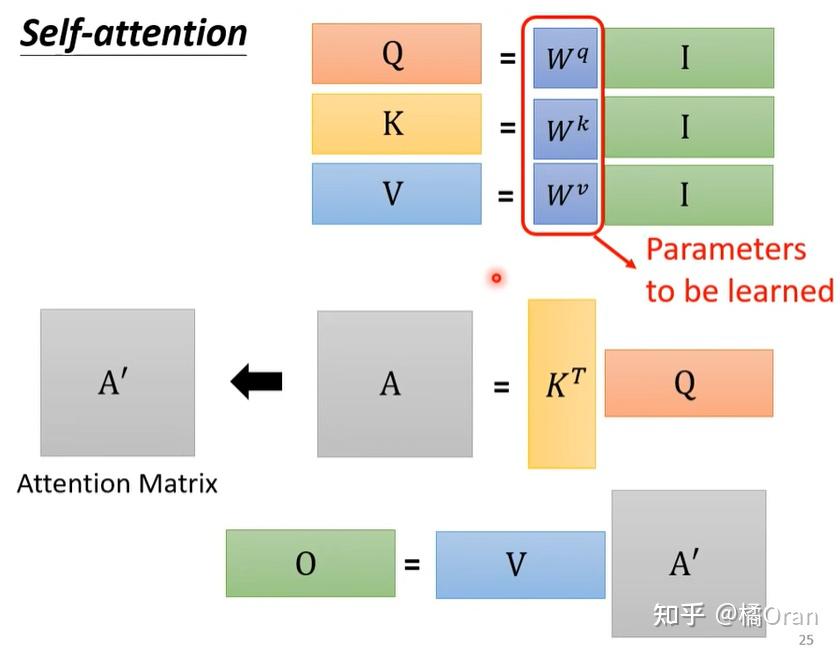
Scaled Dot-Product Attention
Transformer里的注意力就叫Scaled Dot-Product Attention
我们刚刚完成的计算差不多就是Transformer里的注意力,这种计算在论文里叫做放缩点乘注意力(Scaled Dot-Product Attention)。它的公式是:
K就是key向量的数组,也就是:
K = [[1, 2, 0], [1, 2, 0], [0, 0, 2], [1, 4, 0]] V是value向量数组
刚才的例子只做了一次查询,操作写为:
其中,query q就是[1, 0, 0]了。
实际上,我们可以一次做多组query。把所有
打包成矩阵Q,就得到了公式
论文里把value向量的长度叫做
为什么要用一个和
计算相似度不止点乘这一个方法,另一种常用的注意力函数叫做加性注意力,它用一个单层神经网络来计算两个向量的相似度。相比之下,点乘注意力算起来快一些。出于性能上的考量,论文使用了点乘注意力。
自注意力机制
自注意力也是一种注意力机制,只不过它计算序列中某个词和其他所有词的权重。
这个查询query,不是来自外部(数据库的例子),而是从序列本身出发,所以叫self。
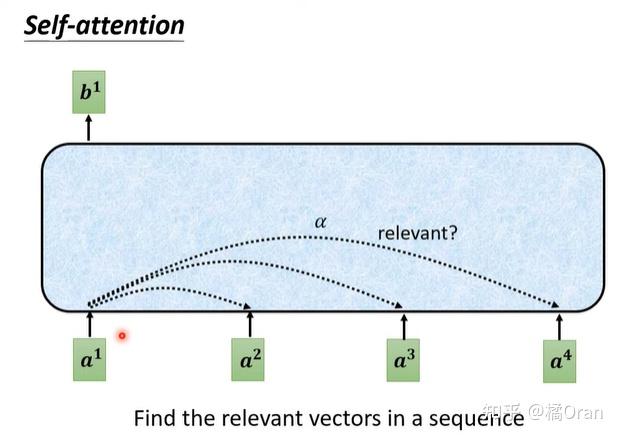
如何产生 b1 这个向量?需要衡量输入向量之间的关联度 α。
计算 attention 的模组算出α(关联度大小),有很多方法,比如 Dot-product 方法和 Additive 方法。
下文主要是讲 Dot-product 方法,这是最常用的方法,也是 Transformer 中用的方法。
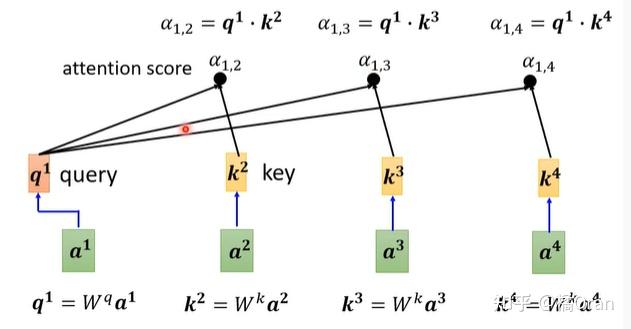
这个过程要重复进行,在实际中,每个向量向量和自己、和其他向量都要做一次。
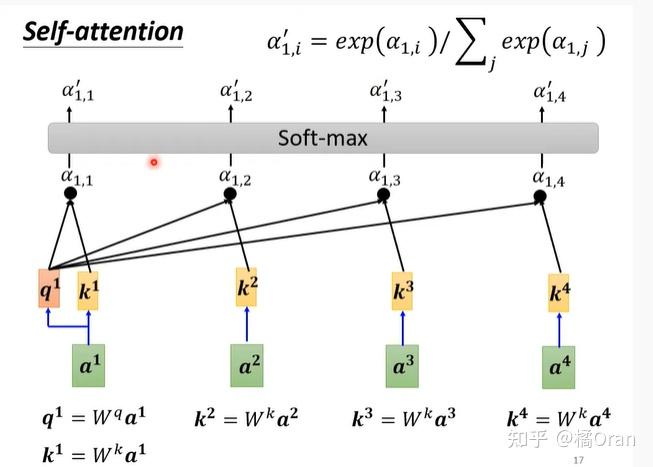
得出所有的
最后还需要一个v来抽取信息。
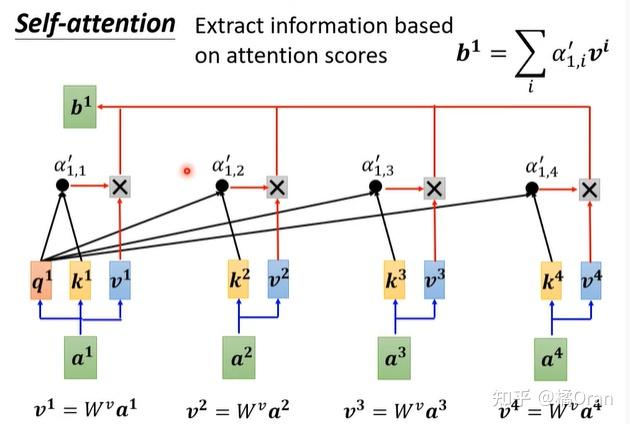
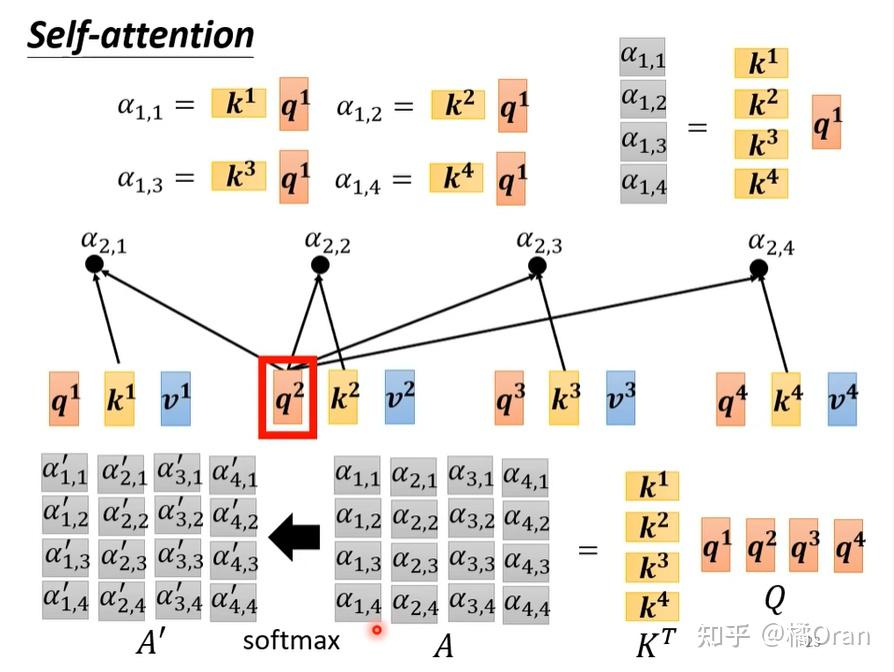
上面计算b的过程,可以并行计算。
多头注意力机制
一种 relevance 还不够,需要多种 relevance。也即是需要多个 q,k,v
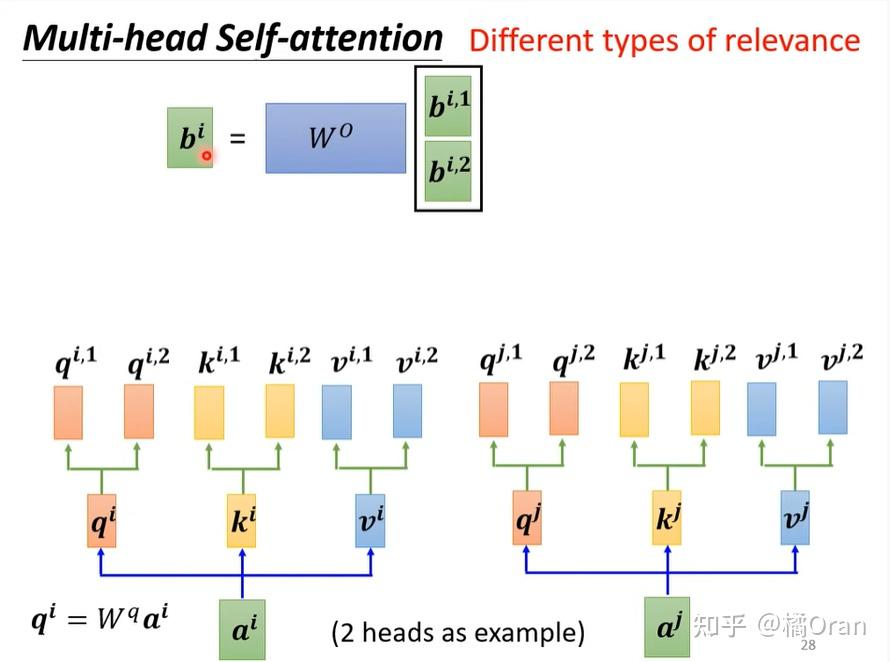
其中h是”头“数,
Transformer 模型架构
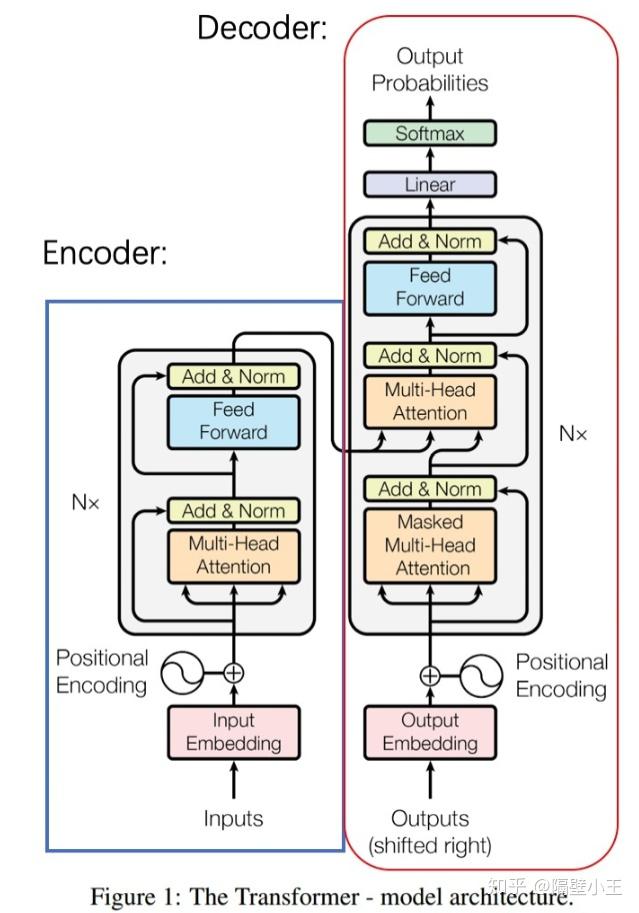
主要讲下数据从输入到encoder到decoder输出这个过程中的流程(以机器翻译为例子):
Encoder
对于机器翻译来说,一个样本是由原始句子和翻译后的句子组成的。比如原始句子是: “我爱机器学习”,那么翻译后是 ’i love machine learning‘。 则该一个样本就是由“我爱机器学习”和 “i love machine learning” 组成。
这个样本的原始句子的单词长度是length=4,即‘我’ ‘爱’ ‘机器’ ‘学习’。经过embedding后每个词的embedding向量是512。那么“我爱机器学习”这个句子的embedding后的维度是[4,512 ] (若是批量输入,则embedding后的维度是[batch, 4, 512])。
Padding
因为每个样本的原始句子的长度是不一样的,那么怎么能统一输入到encoder呢。此时padding操作登场了,假设样本中句子的最大长度是10,那么对于长度不足10的句子,需要补足到10个长度,shape就变为[10, 512], 补全的位置上的embedding数值自然就是0了
对于输入序列一般我们都要进行padding补齐,也就是说设定一个统一长度N,在较短的序列后面填充0到长度为N。
对于那些补零的数据来说,我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样经过softmax后,这些位置的权重就会接近0。
Transformer的padding mask实际上是一个张量,每个值都是一个Boolean,值为false的地方就是要进行处理的地方。
Positional Embedding
得到补全后的句子embedding向量后,直接输入encoder的话,那么是没有考虑到句子中的位置顺序关系的。无论是RNN还是CNN,都能自然地利用到序列的先后顺序这一信息。然而,Transformer的主干网络并不能利用到序列顺序信息,它本身不知道词的顺序。所以必须额外告诉模型每个词的位置,否则它会把“猫→垫子”和“垫子→猫”当成一样的情况(想象你在读一句话:“猫坐在垫子上”。如果把这句话的词打乱成“垫子坐在猫上”,意思就完全反了。)。因此,Transformer使用了一种叫做“位置编码”的机制,对编码器和解码器的嵌入输入做了一些修改,以向模型提供序列顺序信息。
关于positional embedding ,文章提出两种方法:
- Learned Positional Embedding ,这个是绝对位置编码,即直接对不同的位置随机初始化一个postion embedding,这个postion embedding作为参数进行训练。
如果使用1,2,3会导致长序列数值过大(如第1000个词的位置编码是1000),影响数值稳定性,从而影响模型训练。
- Sinusoidal Position Embedding ,相对位置编码,即三角函数编码。
下面详细讲下Sinusoidal Position Embedding 三角函数编码。
Positional Embedding和句子embedding是add操作,那么自然其shape是相同的也是[10, 512] 。
Sinusoidal Positional Embedding具体怎么得来呢,我们可以先思考下,使用绝对位置编码,不同位置对应的positional embedding固然不同,但是位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2与位置3和位置4都只相差1。
这些关于位置的相对含义,模型能够通过绝对位置编码参数学习到吗?此外使用Learned Positional Embedding编码,位置之间没有约束关系,我们只能期待它隐式地学到,是否有更合理的方法能够显示的让模型理解位置的相对关系呢?
肯定是有的,首先由下述公式得到Embedding值:
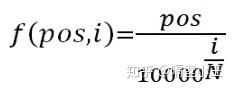
对于句子中的每一个字,其位置pos∈0,1,2,…,9, 每个字是N(512)维向量,维度 i (i∈[ 0,1,2,3,4,..N])带入函数

由于正弦函数能够表达相对位置信息,那么对每个positional embedding进行 sin 或者cos激活,可能效果更好,那就再将偶数列上的embedding值用sin()函数激活,奇数列的embedding值用cos()函数激活得到的具体示意图如下:

这样使用三角函数设计的好处是位置 i 处的单词的psotional embedding可以被位置 i+k 处单词的psotional embedding线性表示,反应两处单词的其相对位置关系。此外位置i和i+k的psotional embedding内积会随着相对位置的递增而减小,从而表征位置的相对距离。
但是不难发现,由于距离的对称性,Sinusoidal Position Encoding虽然能够反映相对位置的距离关系,但是无法区分i和i+j的方向。即pe(i)pe(i+j) =pe(i)pe(i-k) (具体解释参见引用链接1)
残差连接
Transformer使用了和ResNet类似的残差连接,即设模块本身的映射为
。和ResNet不同,Transformer使用的归一化方法是LayerNorm。
另外要注意的是,残差连接有一个要求:输入x和输出F(x)+x的维度必须等长。在Transformer中,包括所有词嵌入在内的向量长度都是
Attention
单头attention 的 Q/K/V 的shape和多头attention 的每个头的Qi/Ki/Vi的大小是不一样的,假如单头attention 的 Q/K/V的参数矩阵WQ/WK/WV的shape分别是512, 512,那么多头attention (假设8个头)的每个头的Qi/Ki/Vi的参数矩阵WQi/WKi/WVi大小是[512, 512/8].
Fedd Forward
架构图中的前馈网络(Feed Forward)其实就是一个全连接网络。具体来说,这个子网络由两个线性层组成,中间用ReLU作为激活函数。
add/Norm
经过add/norm后的隐藏输出的shape也是[10,512]。(当然你也可以规定为[10, x],那么Q/K/V的参数矩阵shape就需要变一下)
encoder输入输出总结
让我们从输入开始,再从头理一遍单个encoder这个过程:
- 输入x
- x 做一个层归一化: x1 = norm(x)
- 进入多头self-attention: x2 = self_attention(x1)
- 残差加成:x3 = x + x2
- 再做个层归一化:x4 = norm(x3)
- 经过前馈网络: x5 = feed_forward(x4)
- 残差加成: x6 = x3 + x5
- 输出x6
以上就是一个Encoder组件所做的全部工作了
Decoder
Decoder中主要除了交叉注意机制,还有一个掩码多头注意力机制。
Masked Multi-Head Attention
掩码机制实现了两个关键目标:
- 防止模型在训练时“偷看”未来答案(避免信息泄漏)
- 允许整个序列的并行计算(提升训练效率)
训练的时候,1.初始decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如
具体的例子如下:
样本:“我/爱/机器/学习”和 “i/ love /machine/ learning”
训练:
把“我/爱/机器/学习”embedding后输入到encoder里去,最后一层的encoder最终输出的outputs [10, 512](假设我们采用的embedding长度为512,而且batch size = 1),此outputs 乘以新的参数矩阵,可以作为decoder里每一层用到的K和V;
将
作为decoder的初始输入,将decoder的最大概率输出词 A1和‘i’做cross entropy计算error。 将
,”i” 作为decoder的输入,将decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。 将
,”i”,”love” 作为decoder的输入,将decoder的最大概率输出词A3和’machine’ 做cross entropy计算error。 将
,”i”,”love “,”machine” 作为decoder的输入,将decoder最大概率输出词A4和‘learning’做cross entropy计算error。 将
,”i”,”love “,”machine”,”learning” 作为decoder的输入,将decoder最大概率输出词A5和终止符</s>做cross entropy计算error。
上述训练过程是挨个单词串行进行的,那么能不能并行进行呢,当然可以。可以看到上述单个句子训练时候,输入到 decoder的分别是
那么为何不将这些输入组成矩阵,进行输入呢?这些输入组成矩阵形式如下:
【
怎么操作得到这个矩阵呢?
将decoder在上述2-6步次的输入补全为一个完整的句子
【
然后将上述矩阵矩阵乘以一个 mask矩阵
【1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
1 1 1 1 1 】
这样是不是就得到了
【
这样的矩阵了 。就是我们需要输入矩阵。这个mask矩阵就是 sequence mask,其实它和encoder中的padding mask 异曲同工。
这样将这个矩阵输入到decoder(其实你可以想一下,此时这个矩阵是不是类似于批处理,矩阵的每行是一个样本,只是每行的样本长度不一样,每行输入后最终得到一个输出概率分布,作为矩阵输入的话一下可以得到5个输出概率分布)。
这样我们就可以进行并行计算进行训练了。
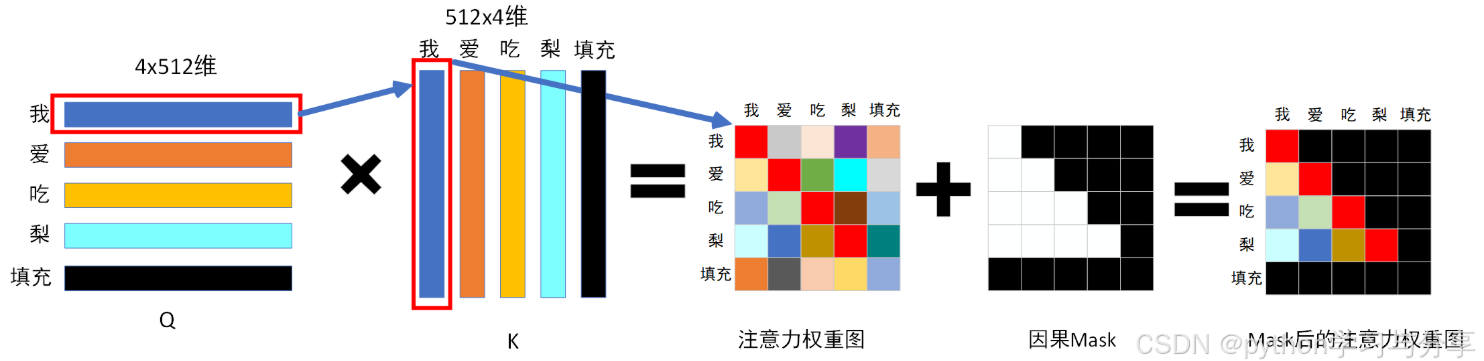
掩码注意力机制的数学公式:(有可能是错的)
上面的公式没有问题,M表示mask矩阵,mask是要在softmax之前操作,所以要放在softmax里面。M矩阵对应位置取负无穷就可以做到了。参考下面的图:
Cross-Attention
之所以叫Cross-Attention,是因为这部分的输入即来自Encoder,也来自Decoder。
这个层比较特别,它的K,V来自
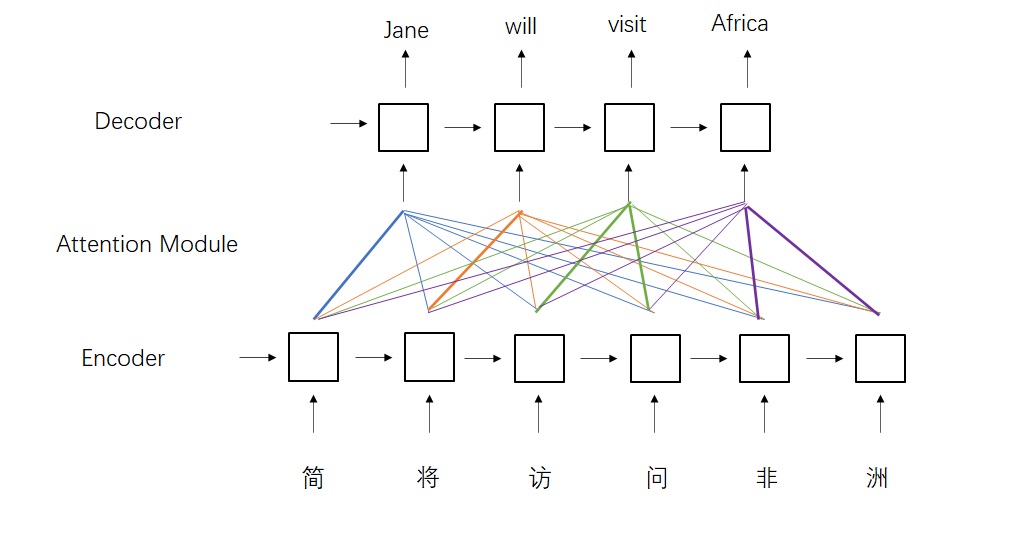
K,V的值是让
测试/推理
训练好模型, 测试的时候,比如用 ‘机器学习很有趣’当作测试样本,得到其英语翻译。
这一句经过encoder后得到输出tensor,送入到decoder(并不是当作decoder的直接输入):
1.然后用起始符
- 用
+ machine 当作输入得到输出 learning
3.用
4.用
5.用
我们就得到了完整的翻译 ‘machine learning is interesting’
可以看到,在测试过程中,只能一个单词一个单词的进行输出,是串行进行的。
相关问题
为什么Decoder部分的输入要用掩码
训练阶段:
输入原始目标序列 [\
结果:模型可能直接复制未来词,而非学习“爱”对应“love”的映射,导致训练无效。
推理阶段:
无影响,因为模型只能依赖已生成的词。
嵌入层权重
![]()
和其他大多数序列转换任务一样,Transformer主干结构的输入输出都是词嵌入序列。词嵌入,其实就是一个把one-hot向量转换成有意义的向量的转换矩阵。在Transformer中,解码器的嵌入层和输出线性层是共享权重的——输出线性层表示的线性变换是嵌入层的逆变换,其目的是把网络输出的嵌入再转换回one-hot向量。如果某任务的输入和输出是同一种语言,那么编码器的嵌入层和解码器的嵌入层也可以共享权重。
“论文中写道:“输入输出的嵌入层和softmax前的线性层共享权重”。这个描述不够清楚。如果输入和输出的不是同一种语言,比如输入中文输出英文,那么共享一个词嵌入是没有意义的。”
上面这段话的意思是:“输入输出的嵌入层和softmax前的线性层共享权重” 这一设计在单语言任务(如文本生成、摘要)中有效,但在跨语言任务(如中译英)中确实不适用。
1. 共享权重的设计背景
适用场景:当输入和输出使用同一种语言的词汇表时(如英文到英文的文本生成),共享权重是合理的。
具体实现:
输入嵌入层(Input Embedding):将输入词(如英文单词)映射为向量。
输出嵌入层(Output Embedding):在生成时,将目标词(同样是英文单词)映射为向量。
Softmax前线性层:将解码器的隐藏状态映射到词汇表空间,生成词的概率分布。
共享权重:输入嵌入矩阵(Embedding Matrix)与Softmax前线性层的权重矩阵(Projection Matrix)共享。
2. 跨语言任务的问题
词汇表差异:
输入语言(如中文)和输出语言(如英文)的词汇表完全不同,共享权重会导致以下问题:
维度不匹配:中文词汇表大小(如50,000词)与英文词汇表大小(如30,000词)不同,矩阵维度无法对齐。
语义不匹配:中文词“苹果”与英文词“apple”虽语义相同,但共享同一嵌入向量会混淆语言特性。
具体矛盾示例:
中文输入词“猫”的嵌入向量被强制映射到英文词“cat”的概率分布,但两者的词汇ID完全不同,导致模型无法学习有效映射。
由于模型要预测一个单词,输出的线性层后面还有一个常规的softmax操作。
Decoder第一个输入是‘开始符’,如何保证正确的预测结果?
问题:
所有句子都是以
回答:
因为还和encoder的输出做了attention。
仔细看transformer的结构图,decoder的初始输入虽然是
Decoder输出的是什么
概率分布。目前还没看明白,后面有空来补
参考链接:https://nlp.seas.harvard.edu/annotated-transformer/
是通过截断最后一行的方式整合的。
假设Tgt加入位置信息编码输入维度为(N,T,W),N为batch大小,T为句子长度,W为编码维度,忽略Batch只考虑单个句子,Decoder最后输出维度和Tgt输入维度一致为(T,W),随后线性层将编码维度W投影到词表维度Vocab_size,得到了(T,Vocab_size)的输出,这时候取最后一行作为预测的下一个词的概率分布,即argmax(out[-1,:] )
参考 nlp.seas.harvard.edu/an 这里面的forward函数。
你说的对,CrossAttention输出文本长度其实只和tgt端 query有关,实际解码时tgt端的文本长度是不断增加的,由于CrossAttention前要对tgt query本身做self attention,为了方便单向解码训练就直接把tgt query直接用矩阵+掩码的形式建模了,所以才会有如此明显的浪费,但是也让优化变得更加简单。
为什么要用自注意力
![]()
自注意力层是一种和循环层和卷积层等效的计算单元。它们的目的都是把一个向量序列映射成另一个向量序列,比如说编码器把x映射成中间表示z
。论文比较了三个指标:每一层的计算复杂度、串行操作的复杂度、最大路径长度。
前两个指标很容易懂,第三个指标最大路径长度需要解释一下。最大路径长度表示数据从某个位置传递到另一个位置的最大长度。比如对边长为n的图像做普通卷积操作,卷积核大小3x3,要做
- 可以并行
- 计算复杂度会降低(这里指改进后的,让每个元素查询最近的r个元素)
- 最大路径长度降低,因为是全局查询,可以在
Q,K,V相关问题
什么是Q,K,V
输入数据(原始输入数据经过词嵌入和嵌入位置编码后)经过三种不同功能的线性变化后得到的矩阵。
Q:当前字词计算与其他字词相关性的矩阵
K:其他字词与Q计算相关性的矩阵
V:对Q-K相关性进行加权求和的矩阵
为什么需要Q,K,V三个不同的矩阵,而不是一个或两个
三个矩阵能保证模型表达能力最大化的同时,不会进一步增大计算量。
如果使用两个矩阵
我们可以理解为任意两个矩阵相同。
若Q和K共享矩阵(Q=K),则查询和匹配依据被强行绑定,模型无法区分“需要找什么”和“能被找到的特征”,导致注意力(注意力就是权重)计算失效。
若K和V共享矩阵(K=V),则匹配依据与实际内容被强制一致,模型无法区分“哪些特征用于匹配”和“哪些信息需要传递”。
若Q和V共享矩阵(Q=V),模型无法区分“需要关注什么”(Q)和“实际传递什么”(V)。(从公式角度来说,Q既用于计算权重,又作为被加权的值,导致信息重复压缩。这个和K=V是一样的)
从数学的角度来说,Q,K,V经过线性变化讲输入映射到不同空间,合并矩阵会导致投影空间被压缩,限制模型的表达能力。
如果使用一个矩阵
如果只使用一个矩阵,那么模型退化为普通的前馈网格,无法捕捉长距离依赖和上下文关系。
注意力理解
https://www.zhihu.com/tardis/zm/art/414084879?source_id=1003
Transformer中最核心的是Attention机制,该机制最核心的公式为:
Self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
讲解这个公式,需要先从向量点乘说起。
向量点乘
从
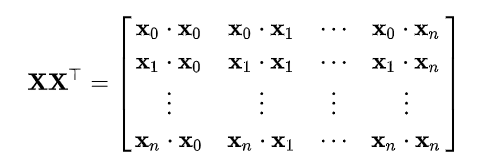
第一行第一列元素为例,其实是向量
下面以词向量矩阵为例,这个矩阵中,每行为一个词的词向量。矩阵与自身的转置相乘,生成了目标矩阵,目标矩阵其实就是一个词的词向量与各个词的词向量的相似度。
加上Softmax,
注意,这里的Softmax是对每一行操作,并不是矩阵全体进行softmax。
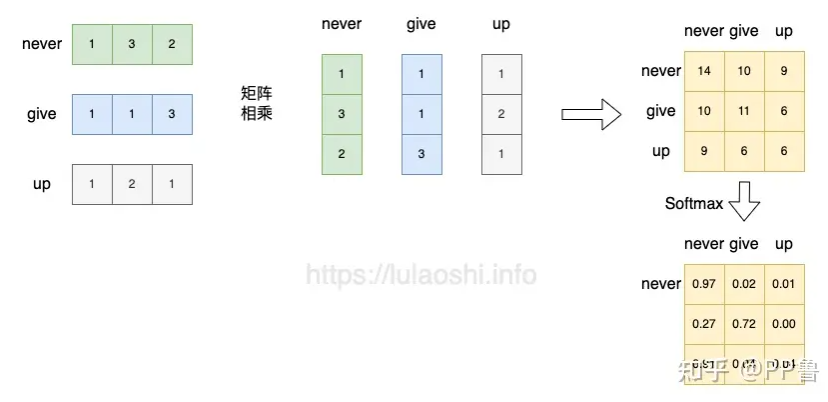
Softmax的作用是对向量做归一化,那么就是对相似度的归一化,得到了一个归一化之后的权重矩阵,矩阵中,某个值的权重越大,表示相似度越高。
在这个基础上,再进一步:
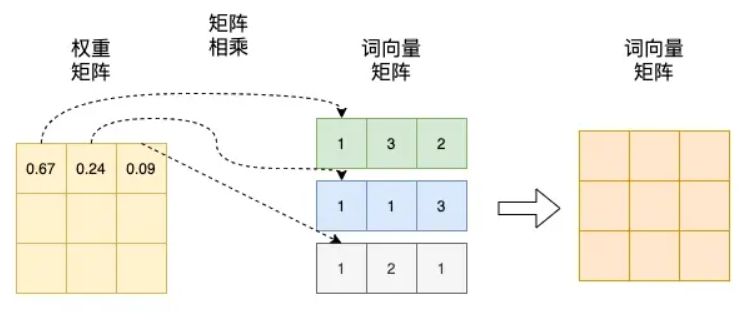
将得到的归一化的权重矩阵与词向量矩阵相乘。权重矩阵中某一行分别与词向量的一列相乘,词向量矩阵的一列其实代表着不同词的某一维度。经过这样一个矩阵相乘,相当于一个加权求和的过程,得到结果词向量是经过加权求和之后的新表示,而权重矩阵是经过相似度和归一化计算得到的。
Q、K、V
https://blog.csdn.net/qq_41915623/article/details/125161008
https://blog.csdn.net/m0_64148253/article/details/140424469
当查询、键和值来自同一组输入时,每个查询会关注所有的键值对并生成一个注意力输出,由于查询、键值对来自同一组输入,因此被称为自注意力。
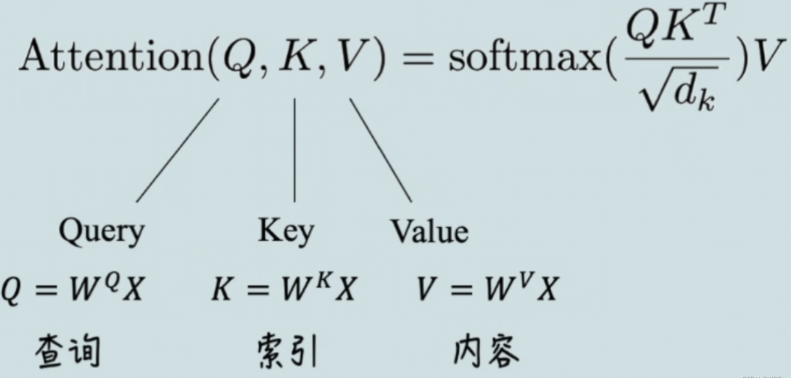
有的地方对Q、K、V的计算为:
当然,对于Q矩阵来说,我们习惯用“行”表示每个token,类似于下图的表示:
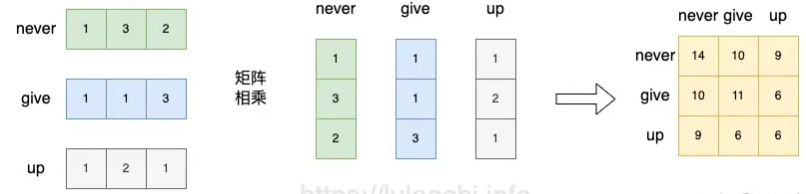
自注意力机制计算过程:
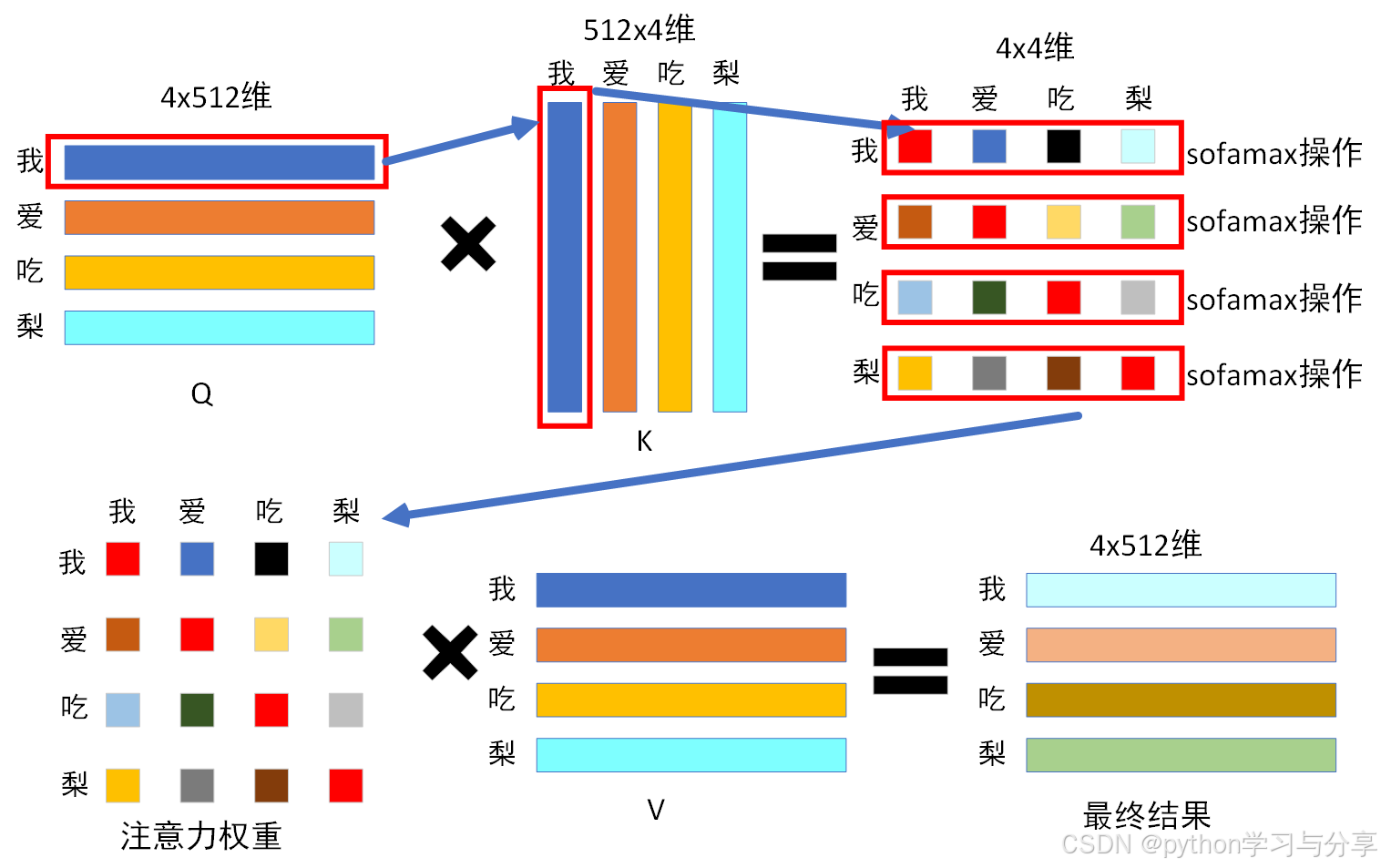
- 注意力权重图中,第1行的4个值分别代表了句子中的’我’字与’我‘,’爱‘,’吃‘,’梨‘这4个字的关联程度,其与自身的关联程度最大(标注红色),其他几行同理。
- 权重图与V相乘得到最终结果。其第一行的每一个元素都是由其他位置的词向量的对应维度进行加权和得到的。(换句话说,每一行的值是由所有行按照注意力权重加权得到的,即每一行都或多或少的包含了其他行的信息。)
补充一个更细致的图: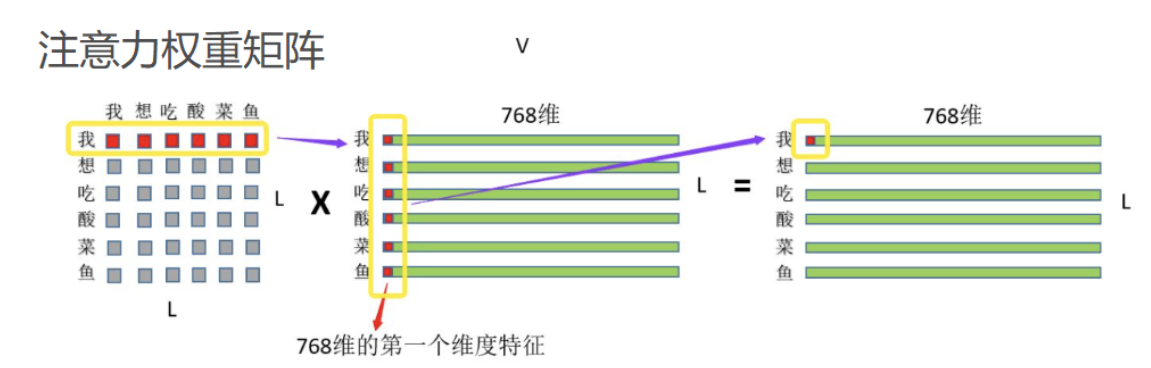
掩码理解
Transformer中的mask有两种,一种是填充mask,还有一种是因果mask。mask是需要在softmax之前进行操作的,也就是在公式softmax()内部使用。
填充mask:为了处理不同长度的输入,对其进行填充。但是这部分不该参与计算。填充负无穷或者0。填充mask在正常的注意力机制中使用
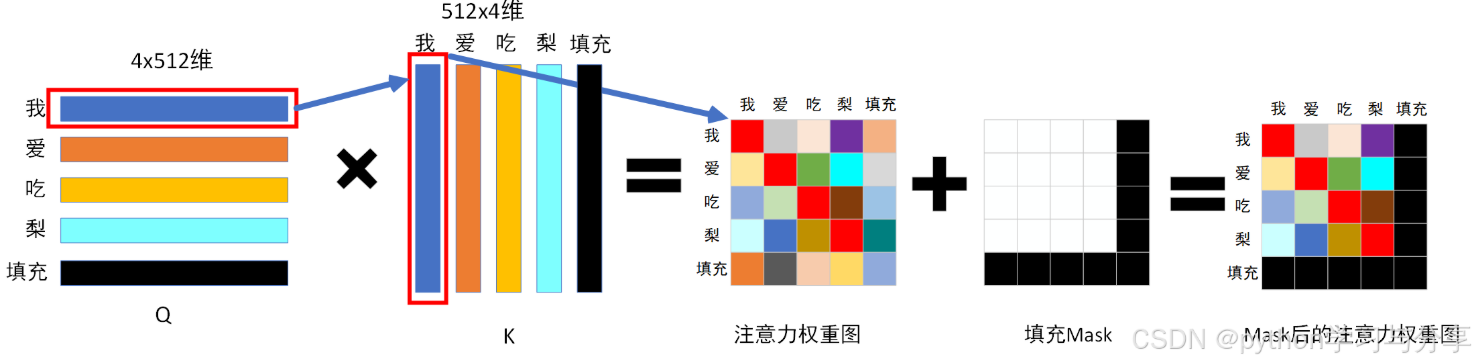
因果mask:不让模型知道未来时间步的信息,在解码器中的掩码注意力机制中使用。
复杂度理解
公式推导
原链接:降低Transformer复杂度O(N^2)的方法汇总(一) - Civ的文章 - 知乎
https://zhuanlan.zhihu.com/p/634406691
我们一般默认Trans的计算复杂度是O(N^2),N表示输入序列的长度,但是有点太草率了。为什么只和N有关,和其他的没关吗?下面来详细解释下:
假设Attention的输入
Attention首先使用线性变换将输入
变换为Query、Key和Value:
(1)
(2)
(3)
由此可以得到Q,K,V的维度:
(4)
(5)
(6)
在常见的Transformer中,通常F=D=M。为了简化符号,后面统一用D来表示。
首先回顾下矩阵乘法的计算复杂度,因为attention的计算复杂度也是矩阵乘法。
对于矩阵
可以理解为:为了计算这两个矩阵的乘积,需要拿矩阵
回到Trans上,乘法一共有两个。
第一次矩阵乘法。结合前面的矩阵乘法复杂度,
第二次矩阵乘法。softmax和
因为这两次矩阵乘法是顺序执行的,所以总的复杂度为它们各自复杂度之和。因为这两个复杂度相等,相加只是引入了一个常数项,所以可以忽略,因此Softmax Attention总的复杂度就为
当我们只关心复杂度与序列长度N之间的关系时,可以忽略D并将其写为
Patchtst中的复杂度
与之相关的是patchtst里面的patch操作。
Batch=32, Channel=7, Seq_Len=96, 假设 Patch_Len=16
在 PatchTST 中,一个 Token(Patch)是指:单个变量(Channel)中,连续的
- 维度reshape: 模型不再认为这是 “32 个包含 7 变量的序列”,而是认为这是 “32 * 7 = 224 个单变量序列”。
对于 Transformer 来说,它正在处理 224 条独立的线,它根本不知道这 224 条线里,其实每 7 条是属于同一个时刻的。 - patch: 现在我们只看这 224 条线中的一条(长度 96)。我们对其进行 Patch 操作。
个 Patch。
这个时候token_num变为6,token_len变为16。 - Embedding:把长度为 16 的原始数据投影到 Transformer 的隐层维度
(比如 )。
计算量从
这时维度变为了(224,6,128)。224可以理解为新的batch_size,或者说一共有224个变量。每个变量经过维度处理后携带的信息为(6,128)。那么就是6个token,每个token的长度为128。对应到attention map里面,就是有6行,每行有128个数据点。只不过每个map里面的计算都是针对单个变量在不同时间点之间的特征,所以patchtst也如它所说是channel independence。
Vardrop中的复杂度
时序预测输入数据的维度是:
传统的时序预测把N表示为输入长度,F表示为变量数,经过嵌入层后,F变为D,然后进行进一步处理。
这时候每个token就是一个时间点的数据,每个时间点的长度为D。那么这个时候计算复杂度就是就为
但是有的论文是反过来操作的,例如VarDrop,把N看为变量数,F看为输入长度。那么这个时候计算复杂度和变量数长度的平方成正比,这个时候如果减小变量数,是可以明显减小计算复杂度的。



